Table of contents
- Introduction
- AWS Chatbot
- AWS Chatbot Pricing
- Setting up AWS Chatbot for Slack
- Step 1: Add the AWS Chatbot app in Slack Automations to your desired Slack workspace
- Step 2: Configure a Slack channel by inviting the AWS Chatbot app to your desired Slack channel
- Step 3: Test notifications
- Sending CloudWatch alarms to Slack
- Sending AWS Health notifications and Security Hub findings to Slack
- AWS Systems Manager – Incident Manager
- Response plans and incident severity classification
- Notification deduplication
- Setting up AWS Systems Manager – Incident Manager
- Configure AWS Systems Manager for your applicable regions with region failover replication set
- Configure contacts for your on-call team
- Configure response plan – Example for type Critical Incident Process
- Configure on-call schedule
- Configure Systems Manager Runbook to be executed for the Critical Incident Process
- Deploying AWS Systems Manager – Incident Manager with Terraform
- Using AWS SSM Incident Manager
- Fire drill
- Incident Manager Pricing
- Conclusion
- References
Introduction
Having a clear understanding of operational service level indicators like service latency and availability is paramount to ensure you can deliver the expected quality of service to your end users, customers and your company. By expected I mean exactly that. Not less, not high above, but mainly at point.
Lower quality of service can manifest into unhappy customers and end users. Higher quality of service can be seen as a good thing, but a too high level can lead to over-engineering, increased complexity, higher cost of over-provisioned capacity and not daring to innovate. Identifying the right level based on conversations with customer stakeholders and aligning expectations through Service Level Agreements and Service Level Objectives can ensure all involved parties share the same understanding of where the bar is. If a stakeholder says “the website must be up and running at all times” people can have different understanding of what this means in practice. Is the stakeholder meaning 99.99%? Or even 100%? Or is 43 minutes over the course of 30 days acceptable? This can lead to very interesting conversations based on operational metrics data instead of subjective opinion.
The first pillar in the AWS Well-Architected Framework is called Operational Excellence, and these are a few of the best practice recommendations that can get you very far, in addition to the Reliability Pillar.
- OPS04-BP01 Identify key performance indicators
- Service Level Indicators such as availability and/or latency
- OPS04-BP02 Implement application telemetry
- OPS04-BP03 Implement user experience telemetry
- OPS10-BP01 Use a process for event, incident, and problem management
- OPS10-BP03 Prioritize operational events based on business impact
- OPS08-BP04 Create actionable alerts
- OPS10-BP04 Define escalation paths
- OPS10-BP06 Communicate status through dashboards
- REL 13. How do you plan for disaster recovery (DR)?
Consider that you have deployed a set of workloads, defined KPIs for five most important end user workflows in the systems, have CloudWatch alarms configured and playbooks defined in an operational wiki about how to handle the events.
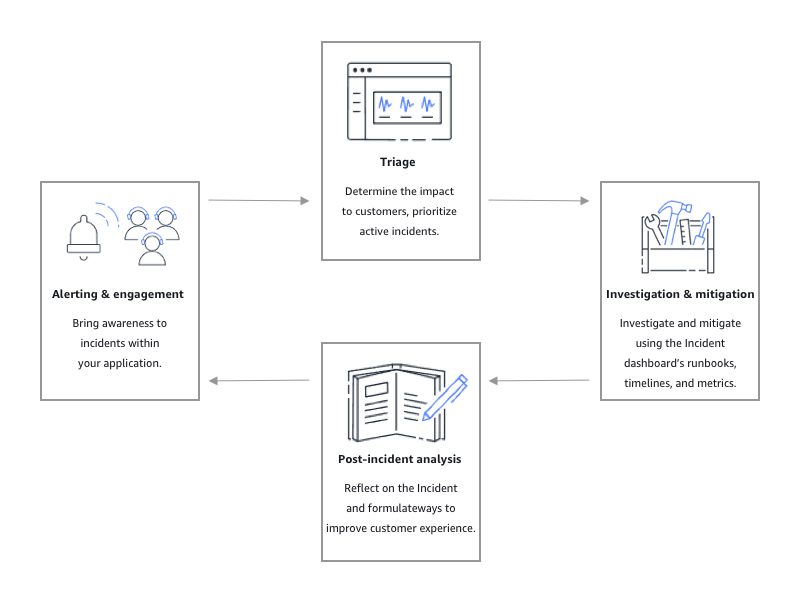
What is your alerting strategy? Many start with CloudWatch Alarms => Simple Notification Service (SNS) => email/Slack, but what happens if multiple alarms have triggered? How do you ensure the right personnel gets notified so that critical alerts aren’t missed, and, know which one(s) to prioritize first?
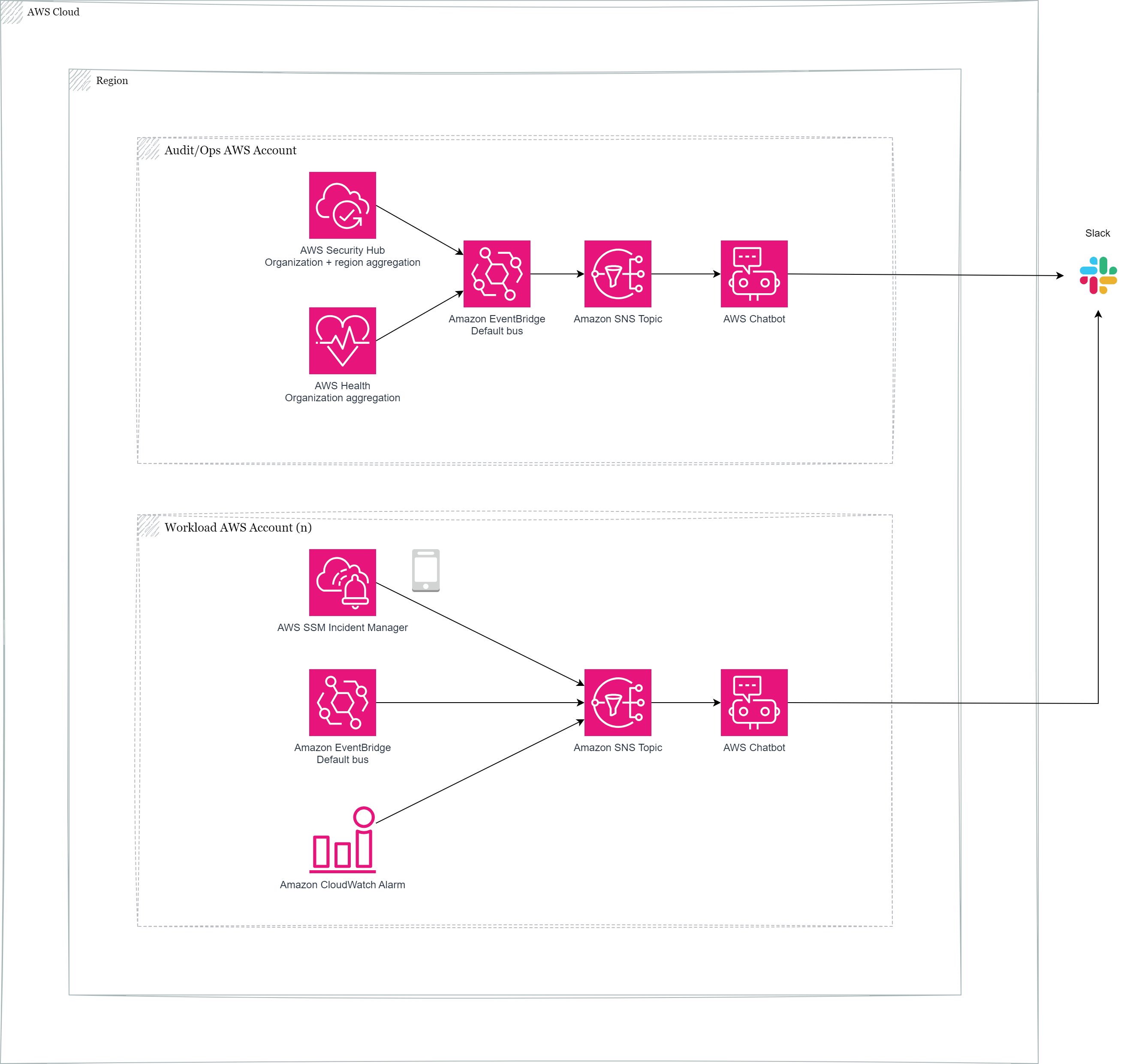
In this blog post we will explore one possible solution which leverages AWS Systems Manager – Incident Manager to efficiently manage situations where a workload has become unavailable or is severely impacted. We will also look into how AWS Chatbot can increase insight and visibility into operational metrics and events by getting data out of the AWS Console and into Slack with examples for events from AWS Health, AWS Security Hub and CloudWatch alarms for a container based workload. I will also demonstrate how you can provision the solution with Terraform.
AWS Chatbot
This is a managed service from AWS which enables ChatOps for AWS. Operational tasks and visibility can be shifted from the AWS Console to Amazon Chime, Microsoft Teams and Slack. You can receive notifications for operational alarms, security alarms, budget deviations and so on. The service eliminates the need for self-managed AWS Lambda functions for these types of integrations, and if your organization is using Slack or Microsoft Teams I can highly recommend to check if you can replace any custom integration logic with AWS Chatbot.
Another useful aspect of AWS Chatbot is the possibility to search and discover AWS information and ask service questions to Amazon Q, without needing to investigate official documentation sources or search on the internet. The answers will be visible to your team so that everyone is kept in the loop. You can also ask Q in VScode if you have a topic you prefer to keep to yourself.
AWS Chatbot Pricing
AWS Chatbot is free to use. You only pay for underlying services (SNS, CloudWatch, GuardDuty, EventBridge, Security Hub) like how you would call them using CLI/Console etc. Slack/Microsoft Teams licensing options will apply as relevant.
Setting up AWS Chatbot for Slack
AWS Chatbot uses Amazon Simple Notification Service (SNS) topic to send event and alarm notifications from AWS services to chat channels you configure. The initial configuration of the service, by authorizing Slack, is only possible through the AWS Console, but the remainder of the solution is possible to provision by using a combination of Terraform providers for AWS. I will take you through the relevant code snippets. Full sample code is available on my GitHub page and further explained in the Conclusion section.
Different organizations have different operational models based on if they are doing centralized platform services or more distributed DevOps style.
If you prefer to centralize the configuration you can do so in one AWS account and have other workload accounts publish events to the central SNS topic. After some experience with AWS Chatbot, and recent resource support in the AWS Cloud Control Provider for Terraform, I’ve landed on that deploying AWS Chatbot in each production workload account can be automated to a high degree and it also reduces complexity for resource access across accounts. One example is that AWS Chatbot automatically can include CloudWatch metrics graphs and useful information.
Each DevOps team can then take full responsibility for their workloads by sending CloudWatch Alarms and EventBridge events from services like AWS Health, AWS Security Hub and Amazon GuardDuty to a team specific Slack/Microsoft Teams channel. A centralized platform team could do the same for aggregated insights for Landing Zone governance as a safety net.
After these Terraform resources have been provisioned, In this case Slack will be demonstrated. Take a note of the output sns_topic_for_aws_chatbot_arn. This will be configured in future sources.
Step 1: Add the AWS Chatbot app in Slack Automations to your desired Slack workspace
- As a Slack workspace administrator, add AWS Chatbot to the Slack workspace.
- Log in to the AWS Console in your respective workload account
- Go to AWS Chatbot console
- Configure a chat client
- Choose Slack, Configure
- Choose the Slack workspace you prefer to use
- Allow

Official reference: https://docs.aws.amazon.com/chatbot/latest/adminguide/slack-setup.html#slack-client-setup.
Step 2: Configure a Slack channel by inviting the AWS Chatbot app to your desired Slack channel
Manual procedure
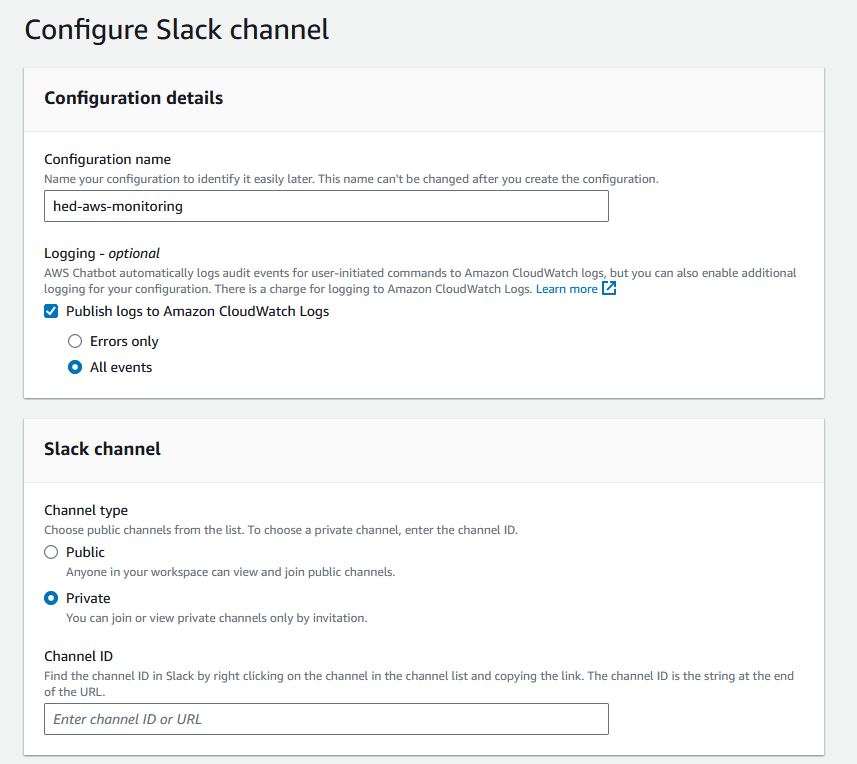
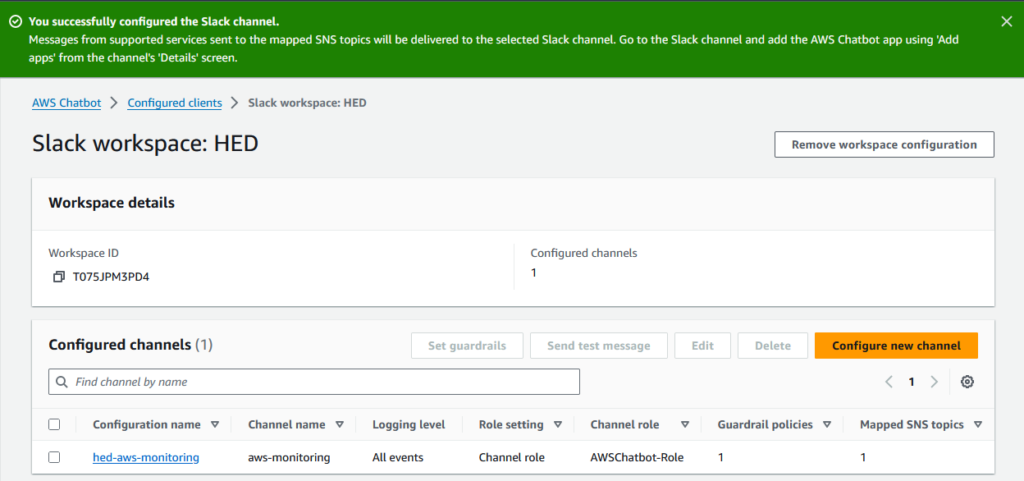
In my case I call the Configuration name “hed-aws-monitoring” and configure event logging to Amazon CloudWatch Logs to be able to ensure that the setup is working as expected and for possible troubleshooting. AWS Chatbot creates this Amazon CloudWatch Logs Group as part of the provisioning phase in us-east-1, it’s not possible (as of June 2024) to configure an existing CloudWatch Logs Group you may have already have provisioned.
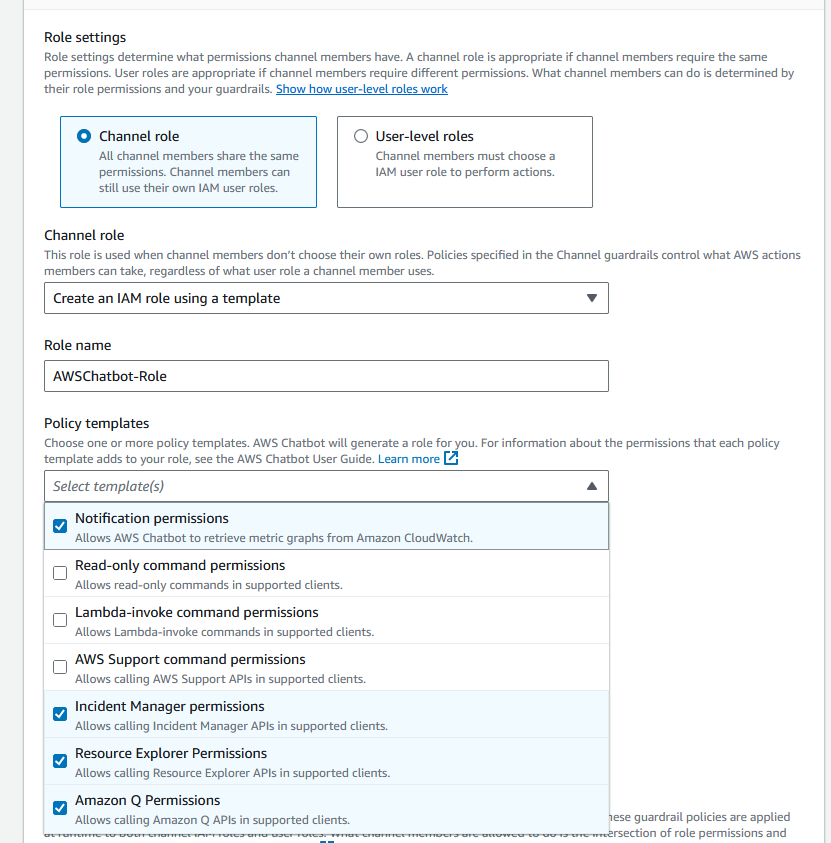
For Role settings I choose to let AWS Chatbot generate the desired IAM configuration. This is possible to define yourself. An approach could be to start with AWS Chatbot generated resources and then replace it your own Terraform resource definitions afterwards.
I choose Notification, Incident Manager, Resource Explorer and Amazon Q permissions. I do not expect to perform read-only commands, invoke Lambda functions or call AWS Support commands directly from Slack, so I leave these unchecked.
The Slack channel is now configured.
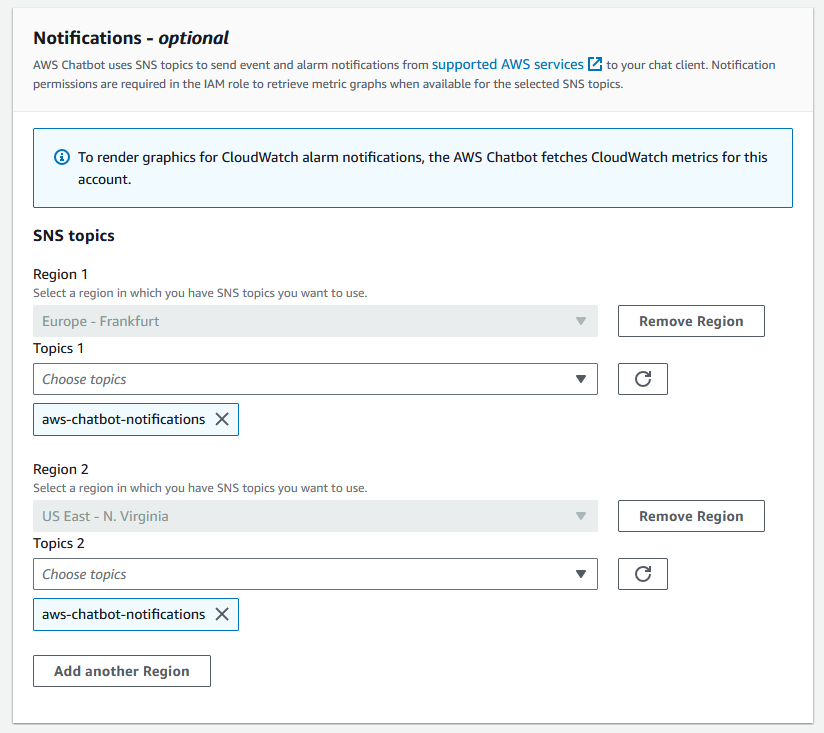
If you want to add support for notifications from global services producing CloudWatch Metrics in us-east-1, such as Route 53 Health Checks, you can configure an additional SNS topic.
Automated deployment with Terraform
A fully working Terraform module is available at https://github.com/haakond/terraform-aws-chatbot/blob/main/README.md.
AWS Chatbot channel configuration for Slack is only supported in the AWS Cloud Control Provider for Terraform, so first we start by declaring the necessary providers:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.53.0"
configuration_aliases = [aws, aws.us-east-1]
}
awscc = {
source = "hashicorp/awscc"
version = "~> 1.2.0"
}
}
}The first resource is the Slack channel configuration with relevant input variables for Slack Channel ID, Slack Workspace ID, and configured SNS topics for primary region and us-east-1, for global service endpoints.
We then declare the IAM role for this purpose with relevant Managed Policies to also be able to managed Incident Manager and Security Hub findings directly from Slack. Feel free to adjust to your use-case. Lastly relevant SNS topic are configured for relevant regions.
resource "awscc_chatbot_slack_channel_configuration" "chatbot_slack" {
configuration_name = var.slack_channel_configuration_name
iam_role_arn = awscc_iam_role.chatbot_channel_role.arn
slack_channel_id = var.slack_channel_id
slack_workspace_id = var.slack_workspace_id
logging_level = var.logging_level
sns_topic_arns = [aws_sns_topic.sns_topic_for_aws_chatbot_primary_region.arn, aws_sns_topic.sns_topic_for_aws_chatbot_us_east_1.arn]
guardrail_policies = [
"arn:aws:iam::aws:policy/PowerUserAccess"
]
}
resource "awscc_iam_role" "chatbot_channel_role" {
role_name = "aws-chatbot-channel-role"
assume_role_policy_document = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Sid = "Chatbot"
Principal = {
Service = "chatbot.amazonaws.com"
}
},
]
})
managed_policy_arns = [
"arn:aws:iam::aws:policy/AWSResourceExplorerReadOnlyAccess",
"arn:aws:iam::aws:policy/AWSIncidentManagerResolverAccess",
"arn:aws:iam::aws:policy/AmazonQFullAccess",
"arn:aws:iam::aws:policy/CloudWatchReadOnlyAccess",
"arn:aws:iam::aws:policy/AWSSecurityHubFullAccess",
"arn:aws:iam::aws:policy/AWSSupportAccess"
]
}
resource "aws_sns_topic" "sns_topic_for_aws_chatbot_primary_region" {
#checkov:skip=CKV_AWS_26:
name = "aws-chatbot-notifications"
http_success_feedback_role_arn = aws_iam_role.delivery_status_logging_for_sns_topic.arn
http_failure_feedback_role_arn = aws_iam_role.delivery_status_logging_for_sns_topic.arn
tags = {
Name = "aws_chatbot_notifications"
Service = "monitoring"
}
}
resource "aws_sns_topic" "sns_topic_for_aws_chatbot_us_east_1" {
#checkov:skip=CKV_AWS_26:
provider = aws.us-east-1
name = "aws-chatbot-notifications"
http_success_feedback_role_arn = aws_iam_role.delivery_status_logging_for_sns_topic.arn
http_failure_feedback_role_arn = aws_iam_role.delivery_status_logging_for_sns_topic.arn
tags = {
Name = "aws_chatbot_notifications"
Service = "monitoring"
}
}
# Define SNS topic policy primary region
resource "aws_sns_topic_policy" "sns_topic_policy_for_aws_chatbot_primary_region" {
arn = aws_sns_topic.sns_topic_for_aws_chatbot_primary_region.arn
policy = data.aws_iam_policy_document.sns_topic_policy_for_aws_chatbot_primary_region.json
}
# Define SNS topic policy primary region us-east-1
resource "aws_sns_topic_policy" "sns_topic_policy_for_aws_chatbot_us_east_1" {
provider = aws.us-east-1
arn = aws_sns_topic.sns_topic_for_aws_chatbot_us_east_1.arn
policy = data.aws_iam_policy_document.sns_topic_policy_for_aws_chatbot_us_east_1.json
}
# IAM role for delivery_status_logging_for_sns_topic
resource "aws_iam_role" "delivery_status_logging_for_sns_topic" {
name = "aws-chatbot-delivery-status-logging"
assume_role_policy = data.aws_iam_policy_document.sns_to_cw_logs_assume_role_policy.json
}
resource "aws_iam_policy" "delivery_status_logging_for_sns_topic_policy" {
policy = data.aws_iam_policy_document.sns_to_cw_logs_policy.json
}
resource "aws_iam_role_policy_attachment" "delivery_status_logging_for_sns_topic_attachment" {
role = aws_iam_role.delivery_status_logging_for_sns_topic.name
policy_arn = aws_iam_policy.delivery_status_logging_for_sns_topic_policy.arn
}
Data resources in data.tf for IAM policies etc. are intentionally left out of this blog post, but can be viewed at https://github.com/haakond/terraform-aws-chatbot/blob/main/data.tf.
To deploy this module in your workload account include the following snippets, as explained in examples/main.tf and examples/provider.tf.
module "aws_chatbot_slack" {
source = "git::https://github.com/haakond/terraform-aws-chatbot.git"
providers = {
aws = aws
aws.us-east-1 = aws.us-east-1
awscc = awscc
}
slack_channel_configuration_name = "slack-hed-aws-monitoring"
slack_channel_id = "AABBCC001122DD88"
slack_workspace_id = "ABCD1234EFGH5678"
logging_level = "INFO"
}provider "aws" {
region = var.aws_region
profile = var.profile_cicd
assume_role {
role_arn = "arn:aws:iam::${var.aws_account_id}:role/${var.profile_cicd}"
session_name = "SESSION_NAME"
external_id = "EXTERNAL_ID"
}
}
provider "awscc" {
region = var.aws_region
profile = var.profile_cicd
assume_role = {
role_arn = "arn:aws:iam::${var.aws_account_id}:role/${var.profile_cicd}"
session_name = "SESSION_NAME"
external_id = "EXTERNAL_ID"
}
}
provider "aws" {
alias = "us-east-1"
region = "us-east-1"
profile = var.profile_cicd
assume_role {
role_arn = "arn:aws:iam::${var.aws_account_id}:role/${var.profile_cicd}"
session_name = "SESSION_NAME"
external_id = "EXTERNAL_ID"
}
}Step 3: Test notifications
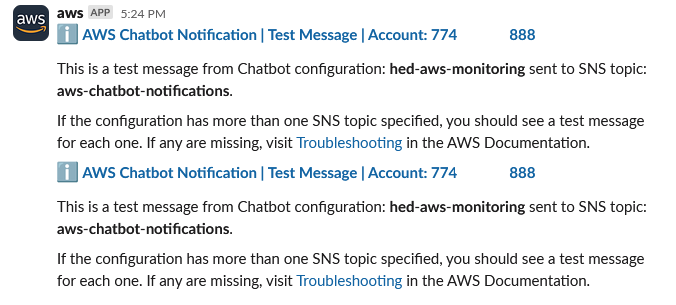
In the Configure channels overview, select the applicable channel and click Send test message.

Expected result: Two messages, one for each SNS topic in us-east-1 and eu-central-1.
I ask Amazon Q via AWS Chatbot about relevant CloudWatch metrics for ECS Fargate container services and get some helpful links in return.

Sending CloudWatch alarms to Slack
You can set up notifications to Slack for any CloudWatch Metric+Alarm that you care about. It can be CPU and memory utilization, disk free space, database query latency and so on. I set up a Route 53 Health Check to monitor my blog availability. This ensures I am being notified regardless of actual reason.
# Define an additional provider for the us-east-1 region.
provider "aws" {
alias = "us-east-1"
region = "us-east-1"
profile = var.profile_cicd
assume_role {
role_arn = "arn:aws:iam::${var.aws_account_id}:role/${var.profile_cicd}"
session_name = "SESSION_NAME"
external_id = "EXTERNAL_ID"
}
}
# AWS Route 53 Health Checks and corresponding metrics reside in us-east-1.
resource "aws_route53_health_check" "hedrange_com_about" {
provider = aws.us-east-1
fqdn = "hedrange.com"
port = 443
type = "HTTPS"
resource_path = "/about/"
failure_threshold = "3"
request_interval = "30"
measure_latency = true
invert_healthcheck = false
regions = ["us-east-1", "us-west-1", "eu-west-1"]
tags = {
Name = "health-check-blog"
}
}
# Since AWS Route 53 Health Checks and corresponding metrics reside in us-east-1, so the alarm has to be provisioned there as well.
resource "aws_cloudwatch_metric_alarm" "healthcheck_hedrange_com_about" {
provider = aws.us-east-1
alarm_name = "health-check-blog-about"
comparison_operator = "LessThanThreshold"
evaluation_periods = "3"
metric_name = "HealthCheckStatus"
namespace = "AWS/Route53"
period = "60"
statistic = "Minimum"
threshold = "1"
alarm_description = "CRITICAL - https://hedrange.com/about is unavailable!"
dimensions = {
HealthCheckId = aws_route53_health_check.hedrange_com_about.id
}
alarm_actions = [local.chatbot_sns_topic_arn_us_east_1]
ok_actions = [local.chatbot_sns_topic_arn_us_east_1]
tags = {
Name = "alarm-health-check-blog",
Severity = "CRITICAL"
}
}To test the notification let’s amend invert_healthcheck = true and re-provision.
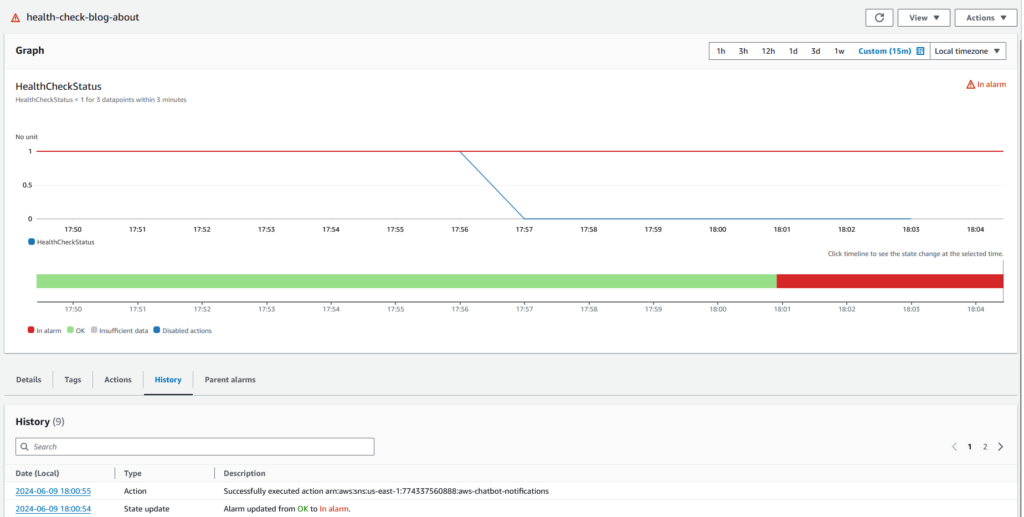
The CloudWatch alarm changed state from OK to In alarm, sent a notification to the SNS topic in us-east-1 configured for AWS Chatbot which then dispatched the following message to Slack:
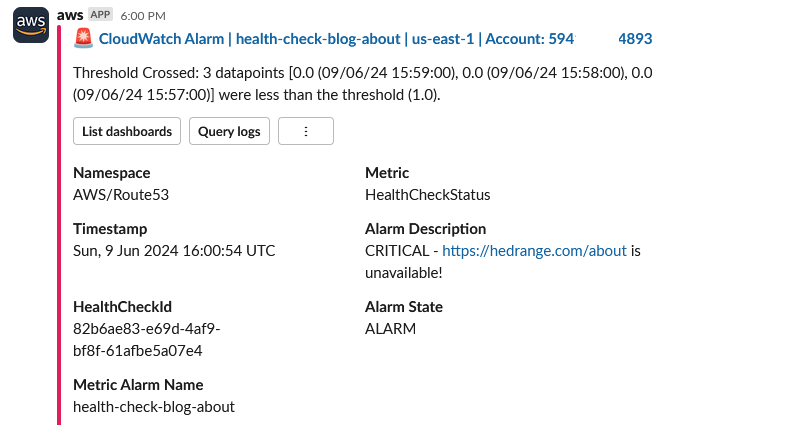
Recovery notification:
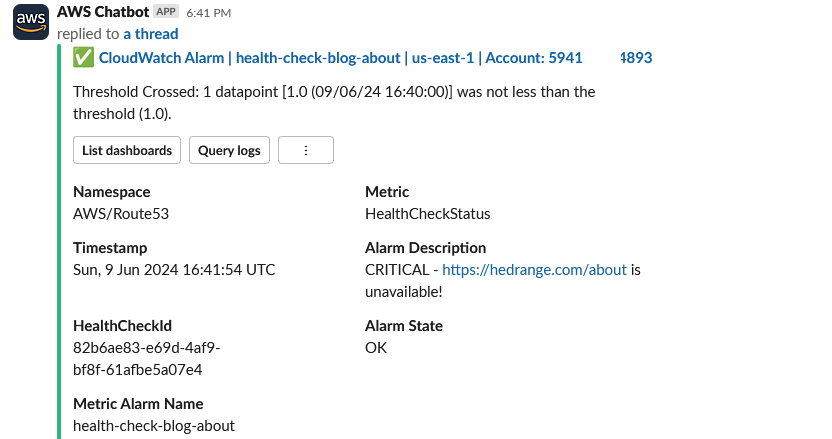
Sending AWS Health notifications and Security Hub findings to Slack
To ensure we also get notified about important AWS Health events and findings in Security Hub we can set up EventBridge rules accordingly.
# Eventbridge rule with event pattern to catch high severity Security Hub findings, regardless of product.
resource "aws_cloudwatch_event_rule" "main_securityhub_event_rule" {
name = "aws-securityhub-rule"
description = "Capture AWS Security Hub events"
event_pattern = <<EOF
{
"source": [
"aws.securityhub"
],
"detail-type": [
"Security Hub Findings - Imported"
],
"detail": {
"findings": {
"Severity": {
"Label": ["CRITICAL", "HIGH"]
}
}
}
}
EOF
}
resource "aws_cloudwatch_event_target" "main_securityhub_rule_target_sns_topic_for_aws_chatbot" {
rule = aws_cloudwatch_event_rule.main_securityhub_event_rule.name
target_id = "SendToSNS"
arn = aws_sns_topic.sns_topic_for_aws_chatbot.arn
}
# Eventbridge rule with event pattern to AWS Health notifications
resource "aws_cloudwatch_event_rule" "health_event_rule" {
name = "aws-health-rule"
description = "Capture AWS Health events"
event_pattern = <<EOF
{
"source": ["aws.health"],
"detail-type": ["AWS Health Event"]
}
EOF
}
# EventBridge rule target to the SNS topic for AWS Chatbot
resource "aws_cloudwatch_event_target" "health_event_rule_target_sns_topic_for_aws_chatbot" {
rule = aws_cloudwatch_event_rule.health_event_rule.name
target_id = "SendToSNS"
arn = aws_sns_topic.sns_topic_for_aws_chatbot.arn
}This is how a Slack message looks like for a High finding in Security Hub about missing IAM Access Analyzer enablement in region eu-north-1.

This is how a notification from AWS Health looks like:
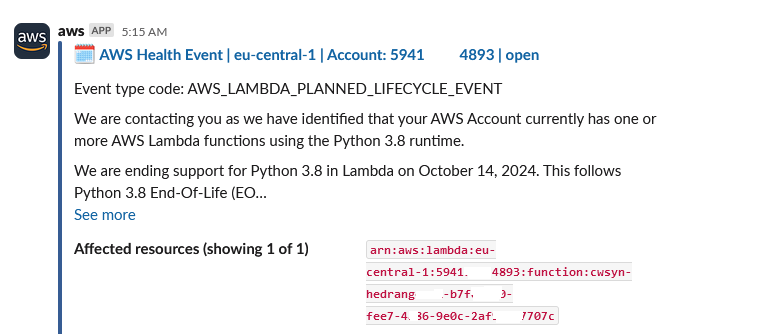
AWS Systems Manager – Incident Manager
Incident Manager is a service that has gone a bit below the radar. Teams adopting this service directly in their AWS environments should be able to minimize Recovery Time Objective and the consequences outages may have for customer applications.
AWS explains that Incident Manager helps reduce the time to resolve incidents by:
- Providing automated plans for efficiently engaging the people responsible for responding to the incidents.
- Providing relevant troubleshooting data.
- Enabling automated response actions by using predefined Automation runbooks.
- Providing methods to collaborate and communicate with all stakeholders.
Response plans and incident severity classification
Events on the AWS platform can trigger Incidents using pre-defined Response Plans to get the attention of first responders, to quickly start troubleshooting while communicating efficiently with the AWS Chatbot integration for Slack and Microsoft Teams.
Based on impact and scope one can differentiate alarms and notifications differentiate between urgency, escalation and resolution procedures.
| Impact code | Impact name | Sample defined scope |
|---|---|---|
1 | Critical | Full application failure that impacts most customers. |
2 | High | Full application failure that impacts a subset of customers. |
3 | Medium | Partial application failure that is customer-impacting. |
4 | Low | Intermittent failures that have limited impact on customers. |
5 | No Impact | Customers aren’t currently impacted but urgent action is needed to avoid impact. |
Notification deduplication
A key feature of AWS SSM Incident Manager is the incident deduplication feature, which ensures grouping of similar notifications, as opposed to direct notifications from CloudWatch => SNS => Slack. Incident Manager automatically deduplicates multiple incidents created by the same Amazon CloudWatch alarm or Amazon EventBridge event. This can reduce alert fatigue and ensure critical notifications aren’t missed.
The purpose of this blog post is not to deep dive into the service itself, but to demonstrate how deployment can be automated with Terraform. For more information read The incident lifecycle in Incident Manager.
Setting up AWS Systems Manager – Incident Manager
At first glance most of the configuration options were not available in the official aws Terraform provider, so many steps had to be configured manually. However, after further searching, I realized that the AWS Cloud Control Terraform provider, awscc, supported the particular resources, so I succeeded in defining a fully working Terraform module for this purpose. I’ve only parameterized the most relevant values. There are many configuration options to tweak so I didn’t make a fully customizable module at this point in time. One approach could be to start here to become familiar and then optimize later on.
Configure AWS Systems Manager for your applicable regions with region failover replication set
resource "aws_ssmincidents_replication_set" "default" {
region {
name = local.current_region
}
region {
name = var.replication_set_fallback_region
}
tags = {
Name = "default"
}
}Configure contacts for your on-call team
I have one primary contact for myself with contact methods email, SMS and voice/phone.
Do not that the resource awscc_ssmcontacts_contact is based on the AWS Cloud Control provider. It it’s not that intuitive that this configuration results in a on-call schedule, so I spent quite some time figuring this out.
resource "aws_ssmcontacts_contact" "primary_contact" {
alias = var.primary_contact_alias
display_name = var.primary_contact_display_name
type = "PERSONAL"
tags = {
key = "primary-contact"
}
depends_on = [aws_ssmincidents_replication_set.default]
}
resource "aws_ssmcontacts_contact_channel" "primary_contact_email" {
contact_id = aws_ssmcontacts_contact.primary_contact.arn
delivery_address {
simple_address = var.primary_contact_email_address
}
name = "primary-contact-email"
type = "EMAIL"
}
resource "aws_ssmcontacts_contact_channel" "primary_contact_sms" {
contact_id = aws_ssmcontacts_contact.primary_contact.arn
delivery_address {
simple_address = var.primary_contact_phone_number
}
name = "primary-contact-sms"
type = "SMS"
}
resource "aws_ssmcontacts_contact_channel" "primary_contact_voice" {
contact_id = aws_ssmcontacts_contact.primary_contact.arn
delivery_address {
simple_address = var.primary_contact_phone_number
}
name = "primary-contact-voice"
type = "VOICE"
}
resource "aws_ssmcontacts_plan" "primary_contact" {
contact_id = aws_ssmcontacts_contact.primary_contact.arn
stage {
duration_in_minutes = 1
target {
channel_target_info {
retry_interval_in_minutes = 5
contact_channel_id = aws_ssmcontacts_contact_channel.primary_contact_email.arn
}
}
}
stage {
duration_in_minutes = 5
target {
channel_target_info {
retry_interval_in_minutes = 5
contact_channel_id = aws_ssmcontacts_contact_channel.primary_contact_sms.arn
}
}
}
stage {
duration_in_minutes = 10
target {
channel_target_info {
retry_interval_in_minutes = 5
contact_channel_id = aws_ssmcontacts_contact_channel.primary_contact_voice.arn
}
}
}
}
resource "awscc_ssmcontacts_contact" "oncall_schedule" {
alias = "default-schedule"
display_name = "default-schedule"
type = "ONCALL_SCHEDULE"
plan = [{
rotation_ids = [aws_ssmcontacts_rotation.business_hours.id]
}]
depends_on = [aws_ssmincidents_replication_set.default]
}Configure response plan – Example for type Critical Incident Process
You can have as many response plans as you like, but each one of them are as of June 2024 priced at $7 on a monthly basis.
One consideration could be to have Critical and High response plans as a starting point and dispatch alarms accordingly.
resource "aws_ssmincidents_response_plan" "critical_incident" {
name = "CRITICAL-INCIDENT"
incident_template {
title = "CRITICAL-INCIDENT"
impact = "1"
incident_tags = {
Name = "CRITICAL-INCIDENT"
}
summary = "Follow CRITICAL INCIDENT process."
}
display_name = "CRITICAL-INCIDENT"
chat_channel = [var.chatbot_sns_topic_notification_arn]
engagements = [awscc_ssmcontacts_contact.oncall_schedule.arn]
action {
ssm_automation {
document_name = aws_ssm_document.critical_incident_runbook.arn
role_arn = aws_iam_role.service_role_for_ssm_incident_manager.arn
document_version = "$LATEST"
target_account = "RESPONSE_PLAN_OWNER_ACCOUNT"
parameter {
name = "Environment"
values = ["Production"]
}
dynamic_parameters = {
resources = "INVOLVED_RESOURCES"
incidentARN = "INCIDENT_RECORD_ARN"
}
}
}
tags = {
Name = "critical-incident-response-plan"
}
depends_on = [aws_ssmincidents_replication_set.default]
}Configure on-call schedule
In this example the on-call rotation schedule consists of only the primary contact. In a full deployment an on-call team normally consists of several people on a weekly schedule, with escalation/fallback. Feel free to adjust to your use-case.
Start of each shift is every Monday at 09:00 and people will be notified from 08:30 – 16:00, during business hours. You can choose any time period of the day, for instance have one on-call schedule during business hours and another one outside of business hours.
resource "aws_ssmcontacts_rotation" "business_hours" {
contact_ids = [
aws_ssmcontacts_contact.primary_contact.arn
]
name = "business-hours"
recurrence {
number_of_on_calls = 1
recurrence_multiplier = 1
weekly_settings {
day_of_week = "MON"
hand_off_time {
hour_of_day = 09
minute_of_hour = 00
}
}
weekly_settings {
day_of_week = "FRI"
hand_off_time {
hour_of_day = 15
minute_of_hour = 55
}
}
shift_coverages {
map_block_key = "MON"
coverage_times {
start {
hour_of_day = 08
minute_of_hour = 30
}
end {
hour_of_day = 16
minute_of_hour = 00
}
}
}
shift_coverages {
map_block_key = "TUE"
coverage_times {
start {
hour_of_day = 08
minute_of_hour = 30
}
end {
hour_of_day = 16
minute_of_hour = 00
}
}
}
shift_coverages {
map_block_key = "WED"
coverage_times {
start {
hour_of_day = 08
minute_of_hour = 30
}
end {
hour_of_day = 16
minute_of_hour = 00
}
}
}
shift_coverages {
map_block_key = "THU"
coverage_times {
start {
hour_of_day = 08
minute_of_hour = 30
}
end {
hour_of_day = 16
minute_of_hour = 00
}
}
}
shift_coverages {
map_block_key = "FRI"
coverage_times {
start {
hour_of_day = 08
minute_of_hour = 30
}
end {
hour_of_day = 16
minute_of_hour = 00
}
}
}
}
start_time = var.rotation_start_time
time_zone_id = "Europe/Oslo"
depends_on = [aws_ssmincidents_replication_set.default]
}Configure Systems Manager Runbook to be executed for the Critical Incident Process
The AWS Systems Manager Runbook AWSIncidents-CriticalIncidentRunbookTemplate can be used as a starting point for this use-case. For more information see Working with Systems Manager Automation runbooks in Incident Manager.
resource "aws_ssm_document" "critical_incident_runbook" {
name = "critical_incident_runbook"
document_type = "Automation"
document_format = "YAML"
content = <<DOC
#
# Original source: AWSIncidents-CriticalIncidentRunbookTemplate
#
# Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
#
# Permission is hereby granted, free of charge, to any person obtaining a copy of this
# software and associated documentation files (the "Software"), to deal in the Software
# without restriction, including without limitation the rights to use, copy, modify,
# merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
# permit persons to whom the Software is furnished to do so.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
# INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
# PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
# HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
# OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
#
---
description: "This document is intended as a template for an incident response runbook in [Incident Manager](https://docs.aws.amazon.com/incident-manager/latest/userguide/index.html).\n\nFor optimal use, create your own automation document by copying the contents of this runbook template and customizing it for your scenario. Then, navigate to your [Response Plan](https://console.aws.amazon.com/systems-manager/incidents/response-plans/home) and associate it with your new automation document; your runbook is automatically started when an incident is created with the associated response plan. For more information, see [Incident Manager - Runbooks](https://docs.aws.amazon.com/incident-manager/latest/userguide/runbooks.html). \v\n\nSuggested customizations include:\n* Updating the text in each step to provide specific guidance and instructions, such as commands to run or links to relevant dashboards\n* Automating actions before triage or diagnosis to gather additional telemetry or diagnostics using aws:executeAwsApi\n* Automating actions in mitigation using aws:executeAutomation, aws:executeScript, or aws:invokeLambdaFunction\n"
schemaVersion: '0.3'
parameters:
Environment:
type: String
incidentARN:
type: String
resources:
type: String
mainSteps:
- name: Triage
action: 'aws:pause'
inputs: {}
description: |-
**Determine customer impact**
* View the **Metrics** tab of the incident or navigate to your [CloudWatch Dashboards](https://console.aws.amazon.com/cloudwatch/home#dashboards:) to find key performance indicators (KPIs) that show the extent of customer impact.
* Use [CloudWatch Synthetics](https://console.aws.amazon.com/cloudwatch/home#synthetics:) and [Contributor Insights](https://console.aws.amazon.com/cloudwatch/home#contributorinsights:) to identify real-time failures in customer workflows.
**Communicate customer impact**
Update the following fields to accurately describe the incident:
* **Title** - The title should be quickly recognizable by the team and specific to the particular incident.
* **Summary** - The summary should contain the most important and up-to-date information to quickly onboard new responders to the incident.
* **Impact** - Select one of the following impact ratings to describe the incident:
* 1 – Critical impact, full application failure that impacts many to all customers.
* 2 – High impact, partial application failure with impact to many customers.
* 3 – Medium impact, the application is providing reduced service to many customers.
* 4 – Low impact, the application is providing reduced service to few customers.
* 5 – No impact, customers are not currently impacted but urgent action is needed to avoid impact.
- name: Diagnosis
action: 'aws:pause'
inputs: {}
description: |
**Rollback**
* Look for recent changes to the production environment that might have caused the incident. Engage the responsible team using the **Contacts** tab of the incident.
* Rollback these changes if possible.
**Locate failures**
* Review metrics and alarms related to your [Application](https://console.aws.amazon.com/systems-manager/appmanager/applications). Add any related metrics and alarms to the **Metrics** tab of the incident.
* Use [CloudWatch ServiceLens](https://console.aws.amazon.com/cloudwatch/home#servicelens:) to troubleshoot issues across multiple services.
* Investigate the possibility of ongoing incidents across your organization. Check for known incidents and issues in AWS using [Personal Health Dashboard](https://console.aws.amazon.com/systems-manager/insights). Add related links to the **Related Items** tab of the incident.
* Avoid going too deep in diagnosing the failure and focus on how to mitigate the customer impact. Update the **Timeline** tab of the incident when a possible diagnosis is identified.
- name: Mitigation
action: 'aws:pause'
description: |-
**Collaborate**
* Communicate any changes or important information from the previous step to the members of the associated chat channel for this incident. Ask for input on possible ways to mitigate customer impact.
* Engage additional contacts or teams using their escalation plan from the **Contacts** tab.
* If necessary, prepare an emergency change request in [Change Manager](https://console.aws.amazon.com/systems-manager/change-manager).
**Implement mitigation**
* Consider re-routing customer traffic or throttling incoming requests to reduce customer impact.
* Look for common runbooks in [Automation](https://console.aws.amazon.com/systems-manager/automation) or run commands using [Run Command](https://.console.aws.amazon.com/systems-manager/run-command).
* Update the **Timeline** tab of the incident when a possible mitigation is identified. If needed, review the mitigation with others in the associated chat channel before proceeding.
inputs: {}
- name: Recovery
action: 'aws:pause'
inputs: {}
description: |-
**Monitor customer impact**
* View the **Metrics** tab of the incident to monitor for recovery of your key performance indicators (KPIs).
* Update the **Impact** field in the incident when customer impact has been reduced or resolved.
**Identify action items**
* Add entries in the **Timeline** tab of the incident to record key decisions and actions taken, including temporary mitigations that might have been implemented.
* Create a **Post-Incident Analysis** when the incident is closed in order to identify and track action items in [OpsCenter](https://console.aws.amazon.com/systems-manager/opsitems).
DOC
}Deploying AWS Systems Manager – Incident Manager with Terraform
In addition to the snippets mentioned above there are resource configurations for IAM and Terraform data objects. To keep in mind the length of this blog post I therefore only refer to them in the full module code repository.
This is how I configure the module call in my workload provisioning pipeline. In a production environment in a DevOps model I would provision this module in every production workload account a DevOps team is responsible for, along with the applications and CloudWatch monitoring data. Feel free to adjust to how your organization is set up.
# Use aws and awscc providers to provision SSM Incident Manager
# Ref. https://registry.terraform.io/providers/hashicorp/aws/latest/docs/guides/using-aws-with-awscc-provider
# Refers to output from the previous module provision for AWS Chatbot.
module "ssm_incident_manager" {
source = "git::https://github.com/haakond/terraform-aws-ssm-incident-manager.git?ref=dev"
providers = {
aws = aws
awscc = awscc
}
primary_contact_alias = "primary-contact"
primary_contact_display_name = "Håkon Eriksen Drange"
primary_contact_email_address = "alpha.bravo@charlie-company.com"
primary_contact_phone_number = "+4799887766"
chatbot_sns_topic_notification_arn = module.aws_chatbot_slack.chatbot_sns_topic_arn_primary_region
rotation_start_time = "2024-06-24T07:00:00+00:00"
}Since we had to use a combination of the aws and awscc Terraform providers, remember to include something similar in your provider.tf:
provider "aws" {
region = var.aws_region
profile = var.profile_cicd
assume_role {
role_arn = "arn:aws:iam::${var.aws_account_id}:role/${var.profile_cicd}"
session_name = "SESSION_NAME"
external_id = "EXTERNAL_ID"
}
}
provider "awscc" {
region = var.aws_region
profile = var.profile_cicd
assume_role = {
role_arn = "arn:aws:iam::${var.aws_account_id}:role/${var.profile_cicd}"
session_name = "SESSION_NAME"
external_id = "EXTERNAL_ID"
}
}Module reference with example: https://github.com/haakond/terraform-aws-ssm-incident-manager/blob/main/examples/main.tf.
Using AWS SSM Incident Manager
Provisioning this module should yield the following results.
Activate contact channels
The first step is to go to Contacts and activate the configured channels.
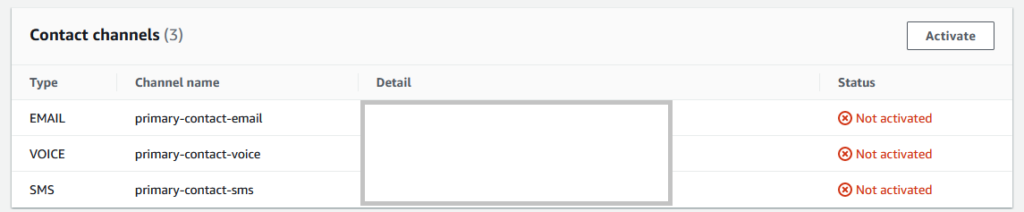
You will receive a one time passcode to each of the configured channels. Each one of them needs to be activated before the contact is enabled.
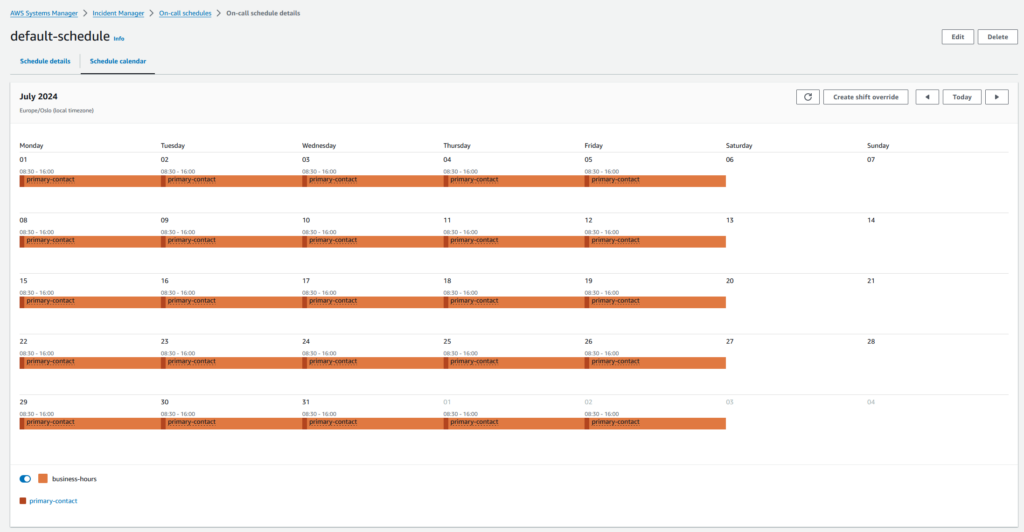
On-call schedule – calendar overview
The configured on-call schedule looks like this. The team will only be notified through the configured contact channels during business hours. I would also set up an out-of-business-hours schedule with the appropriate configuration.
It’s also possible to create shift overrides, in case a team member is asked to cover for a sick colleague etc.
Fire drill
I provisioned a temporary Amazon Linux 2 EC2 instance and set up a CloudWatch alarm to simulate unusual high CPU utilization over an extended period of time where Auto Scaling was not able to provision enough capacity for the load spike. This can be any CloudWatch alarm. Route 53 Health Checks and CloudWatch Synthetics monitors are also be good candidates.
Alarm and OK actions are configured with the relevant SNS topics for AWS Chatbot provisioned in the previous module.
resource "aws_cloudwatch_metric_alarm" "demo_ec2_instance_cpu_utilization" {
alarm_name = "CRITICAL-EC2-CPU_i-04f7af9ea5374c4d8"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "3"
metric_name = "CPUUtilization"
namespace = "AWS/EC2"
period = "300"
statistic = "Average"
threshold = "80"
alarm_description = "CRITICAL CPU utilization for instance ID i-04f7af9ea5374c4d8!"
dimensions = {
InstanceId = "i-04f7af9ea5374c4d8"
}
alarm_actions = [module.aws_chatbot_slack.chatbot_sns_topic_arn_primary_region, module.ssm_incident_manager.critical_incident_response_plan_arn]
ok_actions = [module.aws_chatbot_slack.chatbot_sns_topic_arn_primary_region]
}I log in to the demo EC2 instance through AWS Systems Managed – Session Manager and run the following commands to generate high CPU load for 30 minutes.
sudo amazon-linux-extras install epel -y
sudo yum install stress -y
stress --cpu 4 --timeout 30m
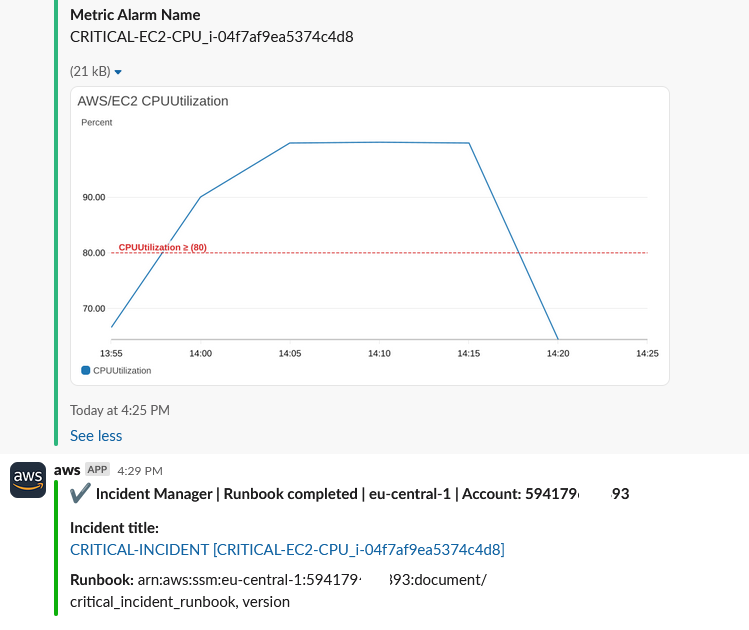
The CloudWatch Alarm dispatches to SNS for AWS Chatbot and the result is the following message on Slack:
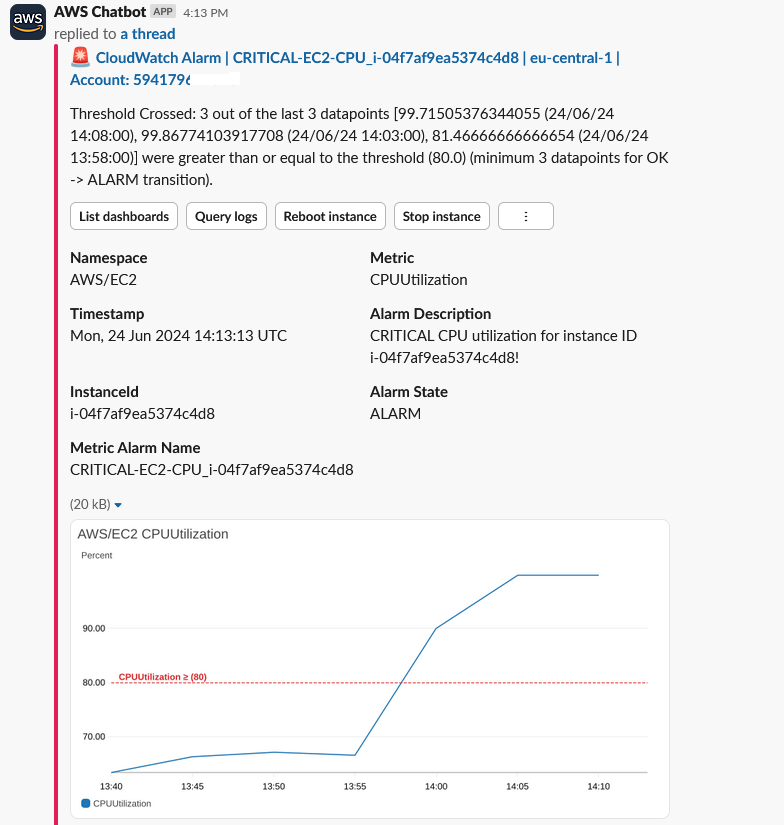
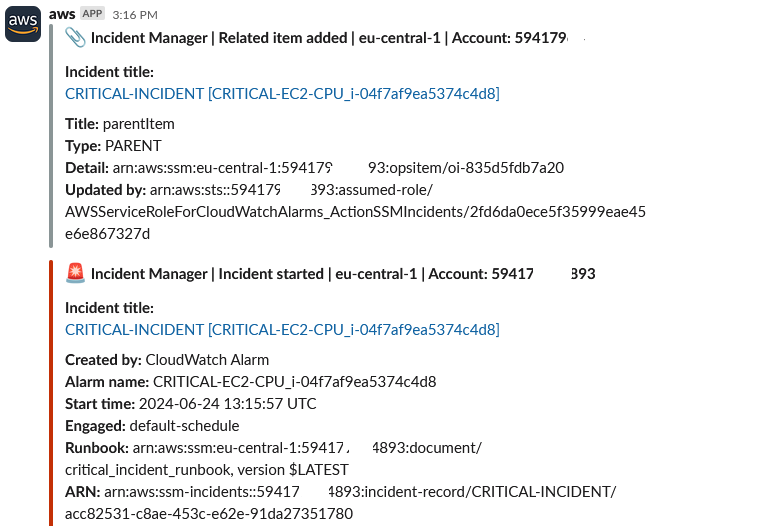
The CloudWatch Alarm’s secondary action is to trigger an AWS Systems Manager – Incident Manager Response Plan, which also is set up to post to Slack:
After 1 minute, as per the contact plan configuration, I receive this email:
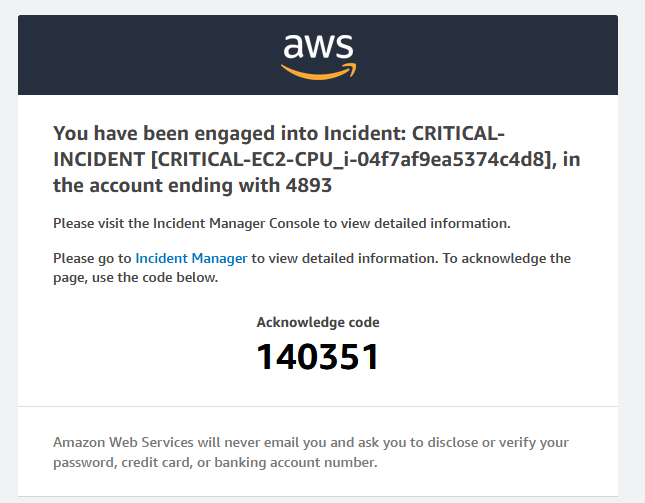
Shortly after I receive this SMS:
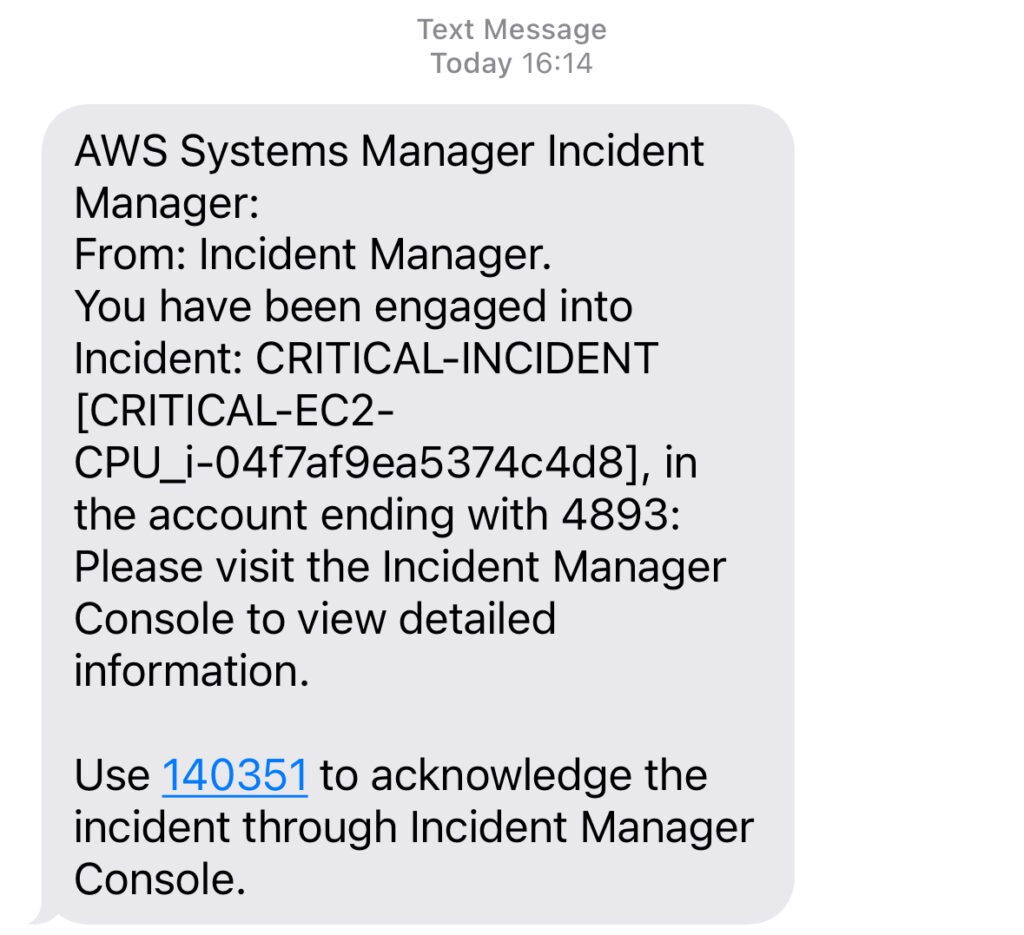
I then follow the instructions to acknowledge the incident:
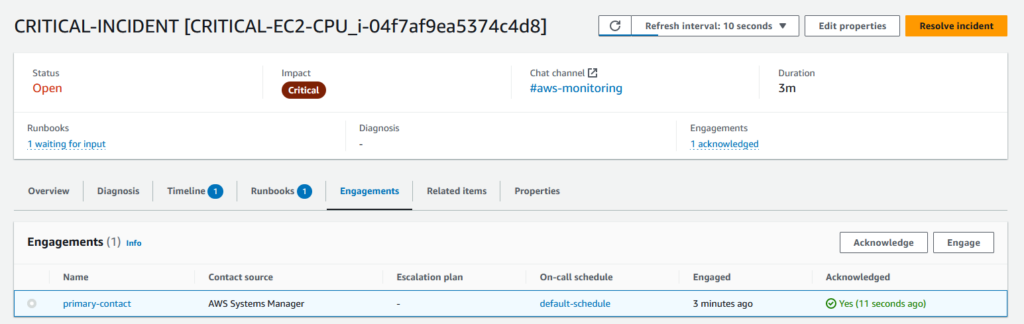
If this was during the night and I was asleep, the next phase would be an automated phone call.
My team-mates can see on Slack that I have assumed ownership of the incident.

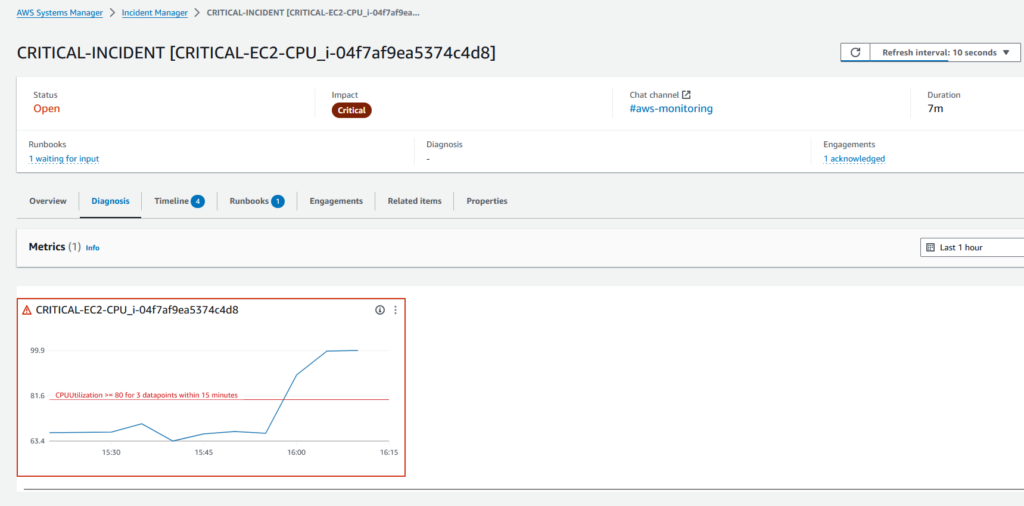
This is how the incident is tracked in AWS Systems Manager – Incident Manager. The SSM runbook as deployed with Terraform is triggered which provides guidance on how to handle the process of type Critical Incident.
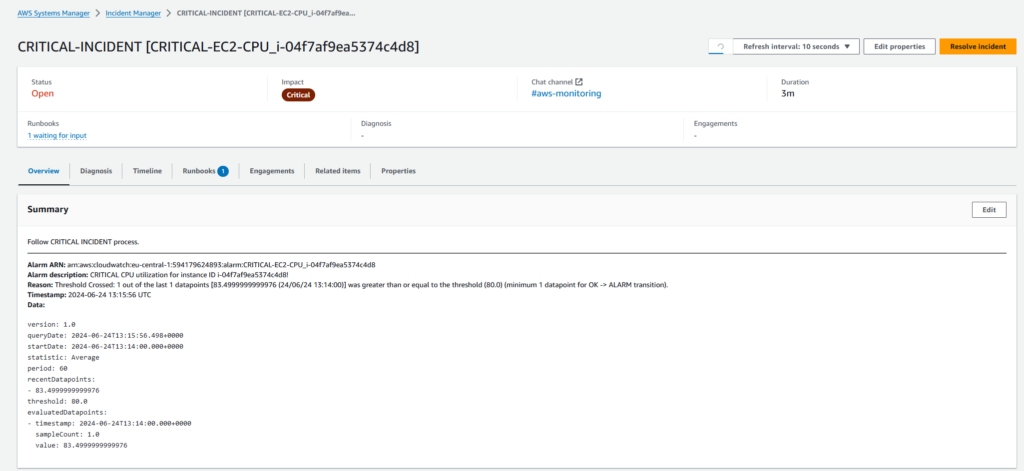
The runbook lays out the process for us and the first step is to examine the customer impact, called Triage.
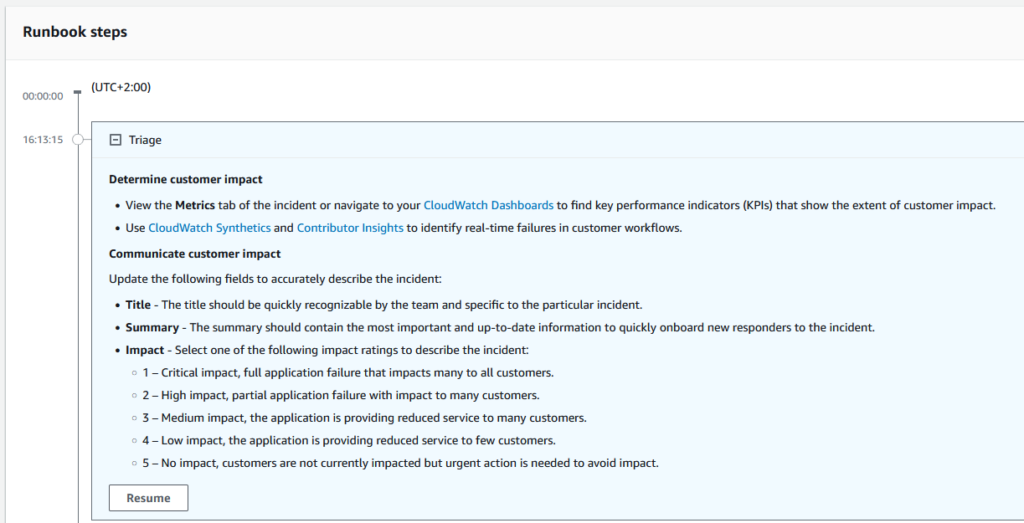
The metric for the CloudWatch Alarm which triggered the Incident is automatically included in the Incident Overview.
Clear instructions are provided for the next phases as well. You can customize all this in your own company runbook.
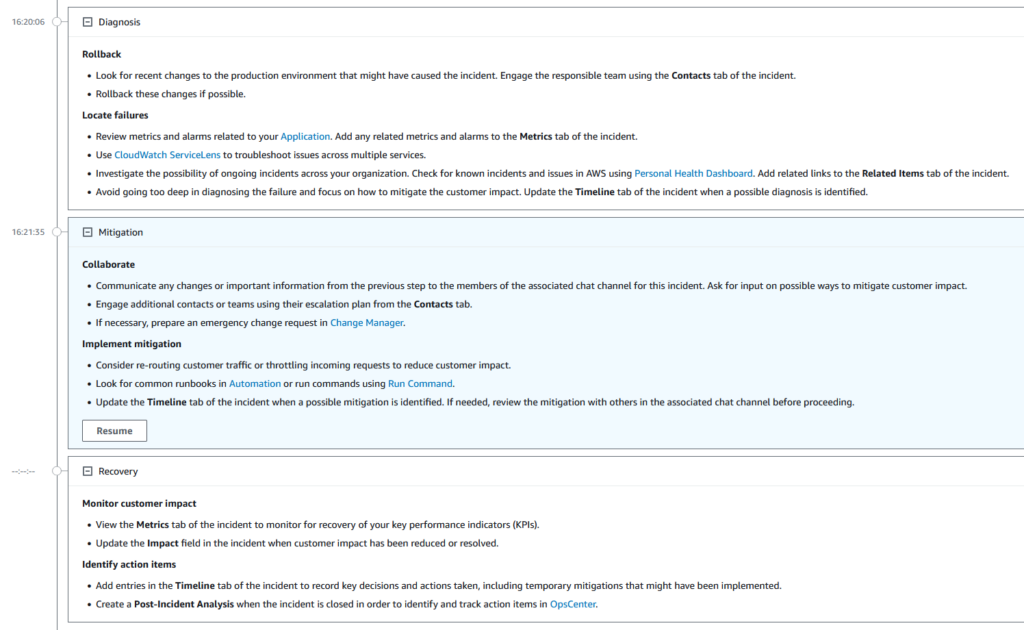
The situation recovered so we complete the Recovery section of the runbook.
Incident Manager provides a full timeline overview of all events, for documentation and further forensics.
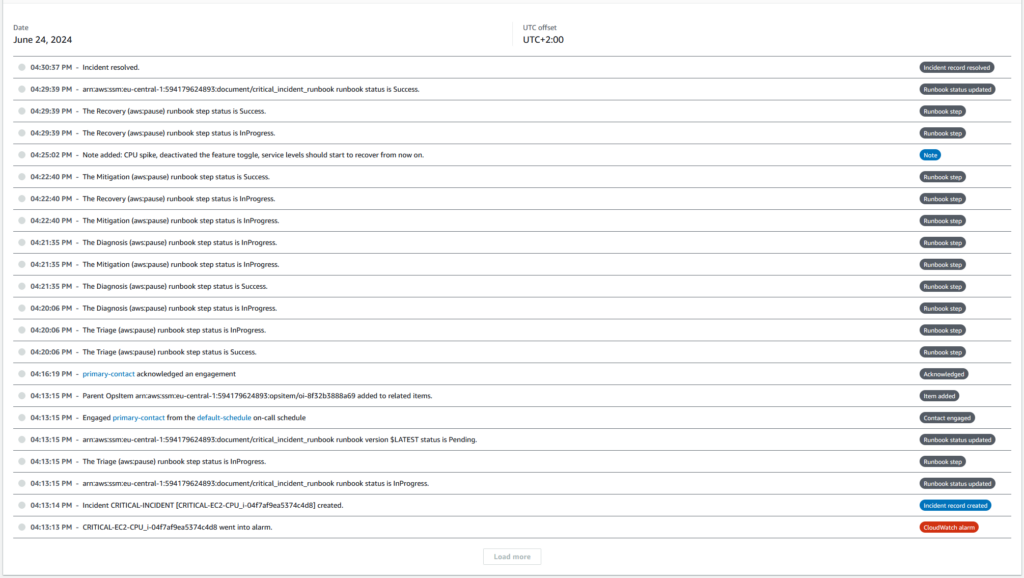
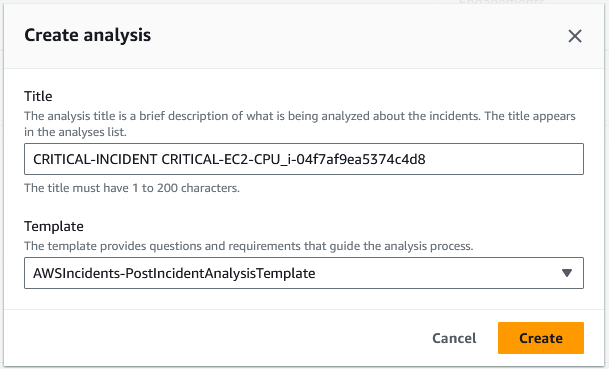
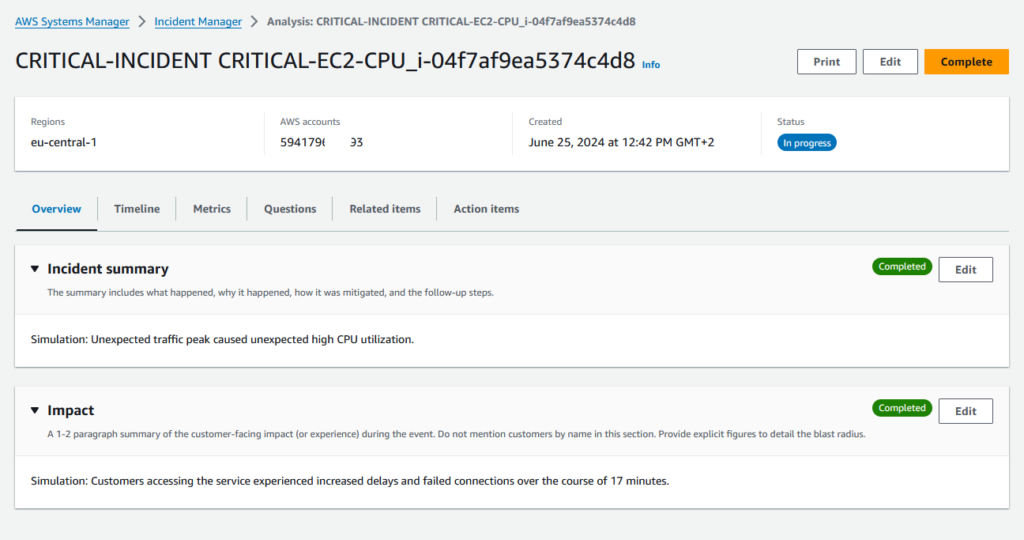
We can then create a post-incident analysis / post-mortem analysis using a recommended template (which also can be customized).
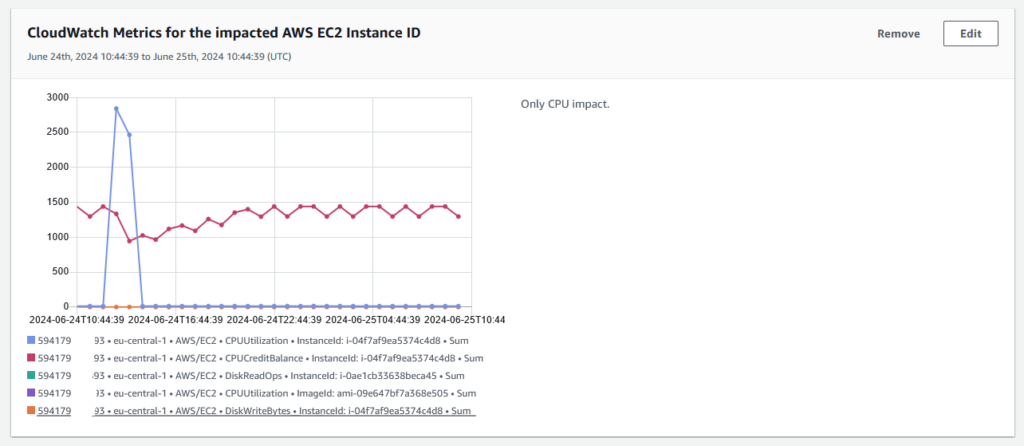
We can pull in relevant CloudWatch metrics to put the event into perspective
Sample questions for a blameless, constructive review about areas that could be improved are also provided:

Follow-up action items can be defined as well.

As we can see AWS Systems Manager – Incident Manager provides functionality for handling the entire lifecycle of critical events.
Incident Manager Pricing
AWS SSM Incident Manager pricing is $7 per Response Plan per month. 100 SMS & Voice messages are included free of charge. Destination country rates can be found here: https://aws.amazon.com/systems-manager/pricing/country-rates/.
Conclusion
In this blog post we explored a solution to ensure operational events are handled efficiently with the primary objective of restoring quality of service and end user experience as quickly as possible. We saw how AWS Chatbot and AWS SSM Incident Manager integrates nicely with AWS services such as AWS Health, AWS Security Hub and any AWS CloudWatch Alarms. Making operational information and CloudWatch metrics available in Slack/Microsoft Teams, where most of the daily interaction takes place, is something that I personally appreciate. Most people have Slack/Teams on their mobile devices so this can really increase the quality of internal communication by not having to log in to the AWS Console or 3rd party systems.
By following the described steps rooted in the AWS Well-Architected Framework and deploying the provided Terraform sample code organizations can improve their operational procedures to increase resiliency and work smart.
Terraform module for AWS Chatbot: https://github.com/haakond/terraform-aws-chatbot/blob/main/README.md.
Terraform module for AWS Systems Manager Incident Manager: https://github.com/haakond/terraform-aws-ssm-incident-manager/blob/main/README.md.
References
- AWS Well-Architected Framework – Operational Excellence Pillar whitepaper
- AWS Well-Architected Framework – Reliability Pillar whitepaper
- What is AWS Chatbot?
- AWS Chatbot – Performing actions
- AWS Systems Manager Incident Manager introduction
- Preparing for incidents in Incident Manager
- Performing a post-incident analysis in Incident Manager
- Product and service integrations with Incident Manager