
Table of contents
The largest outage in history of IT (so far)
On 19 July 2024, the cybersecurity company CrowdStrike distributed a faulty update to its Falcon Sensor security software that caused widespread problems with Microsoft Windows computers running the software. As a result, roughly 8.5 million systems crashed and were unable to properly restart in what has been called the largest outage in the history of information technology and “historic in scale”.
The outage disrupted daily life, businesses, and governments around the world. Many industries were affected; airlines, airports, banks, hotels, hospitals, manufacturing, stock markets, broadcasting, gas stations, retail stores, emergency services and governmental websites. The worldwide financial damage has been estimated to be at least $10 billion.
What happened?
The CrowdStrike Falcon software suite consists, highly simplified, of an software application (agent), which is versioned, and Rapid Response Content configuration updates, the latter not being versioned, to facilitate rapid deployment. However, the outcome of this change was not quality assured properly before widespread deployment. In their Preliminary Post Incident Review, CrowdStrike indicated they promised to improve their quality assurance process and provide customers with “greater control over the delivery of Rapid Response Content updates by allowing granular selection of when and where these updates are deployed.”
I would like to highlight that there are certain nuances to this case (rapid distribution of security detection/mitigation mechanisms, client machines vs. servers etc.), but my personal stance is that any system that is providing mission critical services should have a level of quality assurance that matches it’s Service Level Agreement/Objective and risk tolerance.
Outages like this are not something new. It can happen to any system where changes are applied live or in-place, without being tested properly in advance. Service disruptions can also happen during regular operating system patching procedures, if/when a bug or a security issue is introduced, or with any application or server process, depending on how privileged the process is.
Configuration drift
Long running systems will over the course of time experience configuration drift. A clean server started from a golden image immediately has a high degree of certainty of it’s current state, but as time goes by, certainty decreases. In a traditional (legacy) deployment model, software packages are updated, cache and log files are stored on disk. Perhaps not all log file locations are configured for rotation, perhaps an application stores temp files at a non-standard location and not all temp files are cleaned up. Over time disk space utilization increases, and at some point in the critical partitions, such as /boot may become full without it being noticed. The server’s state has now deviated significantly from its initial state, and it may be hard to reproduce that same state.
A software update that passed QA in staging is not guaranteed be successfully applied in production because of lacking disk space or some trash that has been lying around, accumulating over time, or custom, manual configurations which was supposed to “improve” something in the live environment.
Let’s say you start comparing a green Granny Smith against a green Granny Smith, but over the course of time the green Granny Smith may have evolved to a Red Delicious apple, and perhaps to an orange Asian pear!
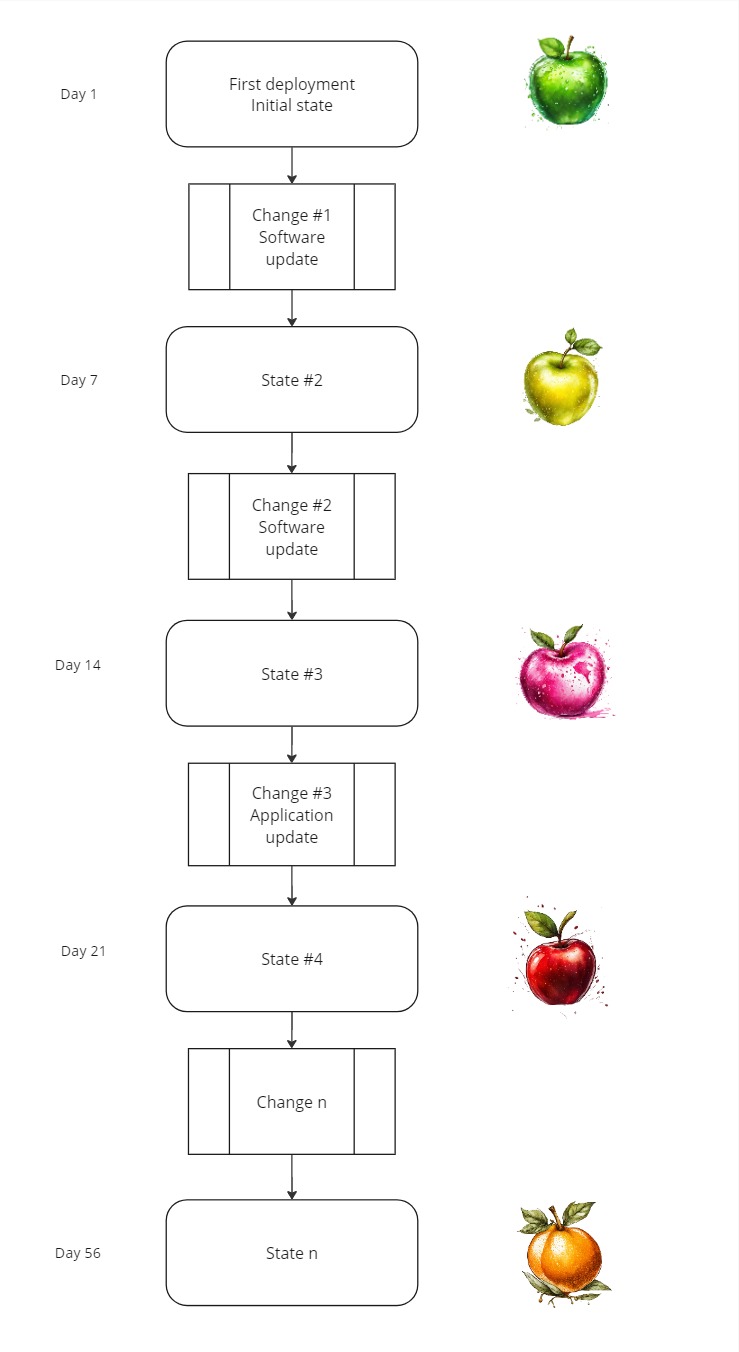
For production systems, especially mission-critical ones, risk management becomes increasingly important. An operating model based on long running servers is prone to introduce risk and uncertainty as time goes by. Staging and production environments can over the course of time drift and not be identical anymore. You end up with a Snowflake Server.
Can the new state be predicted? Can the previously known state be reproduced? If not, you may have a challenge with rollbacks and disaster recovery.
It is a good idea to virtually burn down your servers at regular intervals. A server should be like a phoenix, regularly rising from the ashes.
https://martinfowler.com/bliki/PhoenixServer.html
The concept of Immutable Infrastructure
The Cambridge dictionary definition of Immutability is:
The state of not changing, or being unable to be changed
https://dictionary.cambridge.org/dictionary/english/immutability
With the advent of cloud and more capabilities for automation at our disposal, an alternative pattern called Immutable Infrastructure has gained popularity. The concept is simply about starting from a clean, well-known slate, every time a change is performed.
The concept of the Immutable Server, or disposable servers, was introduced around 2012 by actors such as Thoughtworks, Netflix and Google. Instead of using configuration management to try to keep systems in compliance, they advocated for using configuration management to create base images for servers that could be torn down and rebuilt at will.
An Immutable Server is the logical conclusion of this approach, a server that once deployed, is never modified or changed. No software or operating system updates, security patches, application releases or configuration changes are being performed in-place on live production servers. “Treat your servers like cattle, not like pets” gained traction. If there was a problem with a live server, it would be terminated and replaced by a new one, from a known state.
Not even new application releases/software artifacts, are deployed to existing servers. The running servers are replaced with new instances that has software artifacts built-in. With load balancing, automatic health checks and blue/green or canary capabilities, deploying new servers or rolling back to previous versions can be done without end user impact (if done correctly).
This concept is also described in the AWS Well-Architected Framework – Reliability Pillar – REL08-BP04 Deploy using immutable infrastructure.
Implementing in-place changes to running infrastructure resources, the common approach, is actually stated as an anti-pattern.
Benefits of establishing this best practice:
- Increased consistency across environments: Since there are no differences in infrastructure resources across environments, consistency is increased and testing is simplified.
- Reduction in configuration drifts: By replacing infrastructure resources with a known and version-controlled configuration, the infrastructure is set to a known, tested, and trusted state, avoiding configuration drifts.
- Reliable atomic deployments: Deployments either complete successfully or nothing changes, increasing consistency and reliability in the deployment process.
- Simplified deployments: Deployments are simplified because they don’t need to support upgrades. Upgrades are just new deployments.
- Safer deployments with fast rollback and recovery processes: Deployments are safer because the previous working version is not changed. You can roll back to it if errors are detected.
- Enhanced security posture: By not allowing changes to infrastructure, remote access mechanisms (such as SSH) can be disabled. This reduces the attack vector, improving your organization’s security posture.
Immutable Infrastructure in the AWS Cloud
This practice can be achieved regardless of compute option, but to reduce time to market and operational overhead it mandates a high degree of automation with CI/CD tools such as AWS CodePipeline and GitHub Actions.
Virtual machine based workloads on EC2
In this scenario an automated routine is established which produces virtual machine images called EC2 Amazon Machine Images (AMI). This “golden image” includes the respective version of application source code and it’s dependencies such as operating system services, at the expected versions. AMIs can be produced without environment specific configuration built-in, to be fetched from AWS Systems Manager Parameter Store and/or AWS Secrets Manager, so that the same image can be deployed and verified in dev/test, staging and production environments.
Hashicorp Packer has been available for quite some time. AWS also provides the native service EC2 Image Builder for this purpose.
Amazon provides managed AMIs for both Linux (Amazon Linux based on Fedora) and Windows workloads that are tailored for security and performance in AWS.
With Immutable Infrastructure, Windows Updates and Linux unattended-upgrades are disabled. Every time AWS releases a new officially supported base AMI version, or ad-hoc updates are required, the EC2 Image Builder Pipeline is triggered, which produces a new artifact and validates each change. Every new application version fetches the latest quality assured base AMI and produces a self-contained application AMI.

You can find a Terraform example with inline comments and explanations of EC2 Image Builder resources below .
# EC2 Image Builder component that installs Git and Nginx, clones a sample app repo from GitHub and starts the Nginx web server
resource "aws_imagebuilder_component" "hello_world" {
name = "hello-world-component"
platform = "Linux"
version = "1.0.0"
description = "Hello World application component"
data {
name = "hello-world-app-script"
type = "AWS_LAMBDA"
content = <<-EOF
# Install Git and Nginx
yum install -y git nginx
# Clone sample Hello World app from GitHub
mkdir app-repo
git clone https://github.com/aws-samples/aws-codepipeline-s3-codedeploy-linux app-repo
# Copy cloned files to Nginx public HTML directory
cp -r app-repo/* /usr/share/nginx/html/
# Start Nginx
systemctl start nginx
EOF
}
}
# Recipe named nginx-recipe which includes the nginx-component.
# parent_image is set to Amazon Linux 2 AMI version 2024.7.20. This can be parameterized.
resource "aws_imagebuilder_image_recipe" "nginx_recipe" {
name = "nginx-recipe"
parent_image = "arn:aws:imagebuilder:${var.region}:aws:image/amazon-linux-2-x86/2024.7.20"
version = "1.0.0"
component {
component_arn = aws_imagebuilder_component.nginx.arn
}
}
# Defines an infrastructure configuration, including the instance profile, security group, and subnet (intentionally not included)
resource "aws_imagebuilder_infrastructure_configuration" "nginx_infra" {
name = "nginx-infra"
instance_profile_name = aws_iam_instance_profile.image_builder_instance_profile.name
security_group_ids = [aws_security_group.image_builder_sg.id]
subnet_id = aws_subnet.image_builder_subnet.id
terminate_instance_on_failure = true
}
# Pipeline output should be an Amazon Machine Image (AMI) with a name based on the build date.
resource "aws_imagebuilder_distribution_configuration" "nginx_distribution" {
name = "nginx-distribution"
distribution {
ami_distribution_configuration {
name = "nginx-ami-{{ imagebuilder:buildDate }}"
}
region = var.region
}
}
# Defines the Image Builder pipeline, ties together the recipe, infrastructure configuration, and distribution configuration.
resource "aws_imagebuilder_image_pipeline" "nginx_pipeline" {
name = "nginx-pipeline"
image_recipe_arn = aws_imagebuilder_image_recipe.nginx_recipe.arn
infrastructure_configuration_arn = aws_imagebuilder_infrastructure_configuration.nginx_infra.arn
distribution_configuration_arn = aws_imagebuilder_distribution_configuration.nginx_distribution.arn
}
Container based workloads
In your CI/CD tool of choice, container images are produced and pushed to a container repository such as AWS Elastic Container Registry (ECR). Even though immutability is one of the foundations behind containers, it is not restricted, but based on how the container configuration is specified and launched. Container root filesystems are usually writable by default.
In many cases software packages are being updated on container launch, but this is an anti-pattern in immutability. Update installed packages and install Apache could yield different results if executed at different points in time, as new upstream software package updates are made available. We need to ensure that we test the exact same artifact in staging that is being deployed to production, so the recommended approach is to update all packages at container build time and then launch it with the root storage partition in read only mode.
The container’s root filesystem should be treated as a ‘golden image’ by using Docker run’s
CIS Docker Benchmark control 5.12 – Datadog--read-onlyoption. This prevents any writes to the container’s root filesystem at container runtime and enforces the principle of immutable infrastructure.
Immutability for Docker and local testing
Adding a read-only flag at the container’s runtime enforces the container’s root filesystem being mounted as read only. With the –tmpfs option it is possible to mount a temporary file system for non-persistent data/cache.
docker run <Run arguments> --read-only <Container Image Name or ID> <Command>
# Example with the --tmpfs option to mount a temporary file system for non-persistent data/cache
docker run --interactive --tty --read-only --tmpfs "/run" --tmpfs "/tmp" ubuntu /bin/bashImmutability for workloads provisioned with AWS Elastic Container Service (ECS based on EC2 or Fargate)
Configure the Amazon ECS Task Definition file to set parameter readonlyRootFilesystem in section Storage and logging to true, as the default value is false.
Example Terraform resource definition, see line 27:
resource "aws_ecs_task_definition" "hardened_task_definition" {
family = "hardened-task-definition"
network_mode = "awsvpc"
requires_compatibilities = ["FARGATE"]
cpu = 256
memory = 512
volume {
name = "efs-volume"
efs_volume_configuration {
file_system_id = "fs-0123456789abcdef" # Replace with your EFS file system ID
root_directory = "/tmp"
}
}
container_definitions = jsonencode([
{
name = "hardened-container"
image = "nginx:latest"
essential = true
portMappings = [
{
containerPort = 8080
hostPort = 8080
}
]
readonlyRootFilesystem = true
volumesFrom = [
{
sourceContainer = "efs-volume-container"
}
]
},
{
name = "efs-volume-container"
image = "amazon/amazon-efs-utils:latest"
essential = true
volumeMounts = [
{
name = "efs-volume"
mountPath = "/tmp"
}
]
}
])
}
With this configuration, the /tmp directory inside the hardened-container will be mounted to the specified EFS file system, allowing temporary files to be stored on the persistent EFS file system instead of the read-only root filesystem.
Immutability for workloads provisioned with AWS Elastic Kubernetes Service
This also applies to Kubernetes in general. In the manifest file, specify securityContext: readOnlyRootFilesystem: true.
Example Kubernetes manifest below which demonstrates read only configuration on lines 11-12:
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx
name: hardened-container
securityContext:
readOnlyRootFilesystem: true
volumeMounts:
- name: cache-volume
mountPath: /var/cache/nginx
- name: runtime-volume
mountPath: /var/run
- name: efs-volume
mountPath: /tmp
volumes:
- name: cache-volume
emptyDir: {}
- name: runtime-volume
emptyDir: {}
- name: efs-volume
nfs:
server: efs-server.default.svc.cluster.local
path: "/efs-share"
After applying this updated manifest, the Nginx container will have an Amazon EFS volume mounted at /tmp, allowing it to use the persistent storage provided by Amazon EFS for temporary files while still maintaining a read-only root filesystem.
Leverage Kubernetes’ Deployment strategies for blue/green, canary etc. as best suits your use-case.
About Docker labels/image tags and deployment
When new Docker images are produced and pushed to a container repository, a common approach is to add the label/tag “latest” to it (similar to HEAD in Git), and this is also referenced in CI/CD pipelines. However, with this approach it is challenging to answer exactly which Docker image was in production at any given time, since the reference to the actual image is lost.
To follow through on immutability it is recommended to set a unique tag on every new image. You can reference the actual image tag checksum or some other application specific tag like hello-world-v1.2.3 for GitOps and CI/CD deployment. If you also add a tag with the Git commit ID, debugging becomes much easier.
It also becomes more transparent when dealing with rollbacks when you know hello-world-v1.2.3 was live in production, hello-world-v1.2.4 failed the canary health checks, the automatic procedure rolled back to hello-world-v1.2.3, and you can quickly look up the git commit of hello-world-v1.2.4 for the change.
In Amazon Elastic Container Registry you can prevent image tags from being overwritten by enabling the property Tag immutability.
Immutability for serverless workloads provisioned with AWS Lambda
AWS Lambda is immutable by design. Lambda creates a new version of your function each time that you publish the function. It’s code, runtime, architecture, memory, layers, and most other configuration settings will remain unchanged.
Versions can be used to control function deployment. You can publish a new version of a function for beta testing, or canary testing for a small amount of users instead of deploying the change to all production users at once by using a specific version reference (Qualified ARN instead of $LATEST), in AWS API Gateway or other services that are routing traffic to your Lambda functions.
In the example below we define three aliases: staging, canary-prod and prod, which refers to relevant Lambda function versions. A Lambda routing configuration is defined which directs 90% of the traffic to alias prod (v41), and 10% to alias canary-prod (v42).
Procedure
- Test version 42 in staging.
- Roll out version 42 to 10% of all production users.
- CloudWatch Metrics for Lambda functions are observed and grouped by a combination of alias and executed version.
- If application monitoring and health checks are sustained over a course of eg. 30 minutes with no increases in error rates, update the alias for prod to increase function_version from 41 to 42 and reset routing_config. If not, roll back.
- If health checks are still OK, end. If not, roll back.
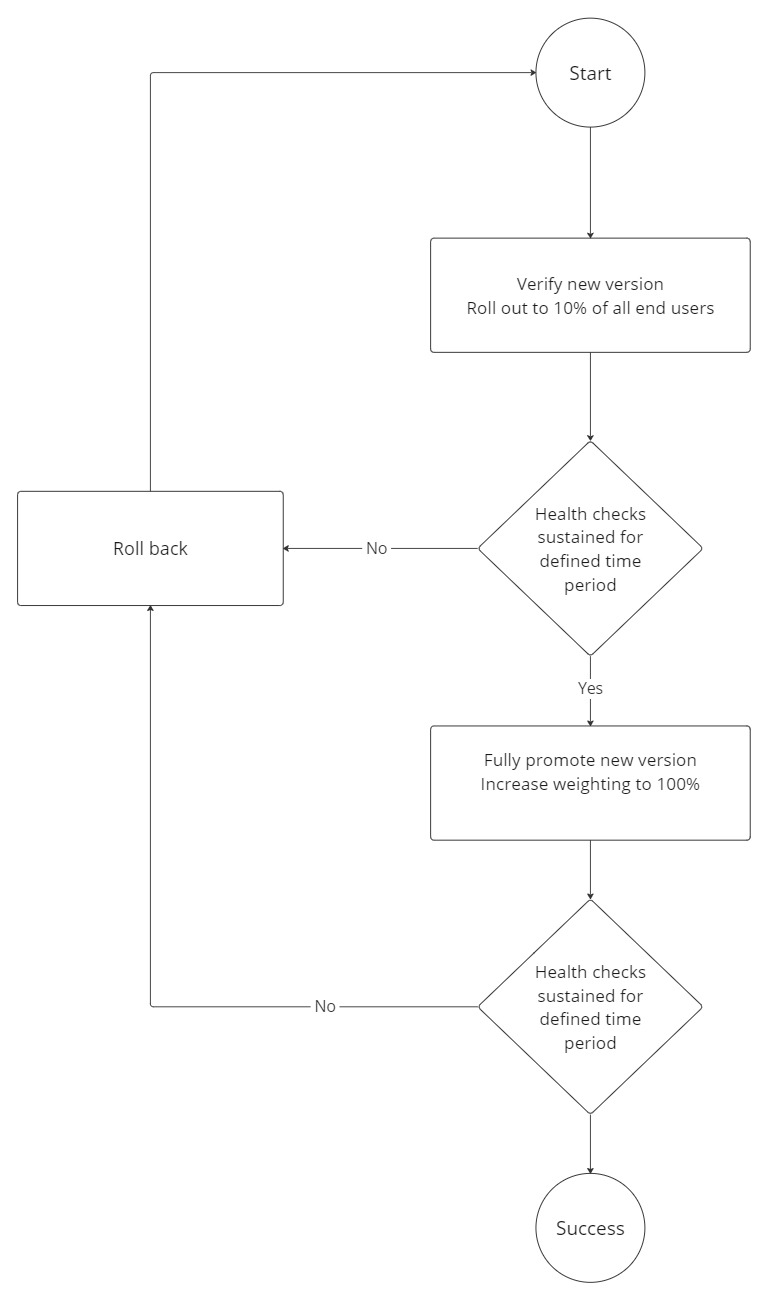
Terraform example of AWS Lambda aliases and routing configuration for canary deployment:
resource "aws_lambda_alias" "staging" {
name = "staging"
function_name = "arn:aws:lambda:aws-region:123456789012:function:helloworld"
function_version = "42"
description = "Canary alias for production environment"
}
resource "aws_lambda_alias" "canary_prod" {
name = "canary-prod"
function_name = "arn:aws:lambda:aws-region:123456789012:function:helloworld"
function_version = "42"
description = "Canary alias for production environment"
}
resource "aws_lambda_alias" "prod" {
name = "prod"
function_name = "arn:aws:lambda:aws-region:123456789012:function:helloworld"
function_version = "41"
description = "Alias for main production audience"
}
resource "aws_lambda_update_alias" "prod_routing_with_canary" {
name = aws_lambda_alias.prod.name
function_name = aws_lambda_alias.prod.function_name
function_version = aws_lambda_alias.prod.function_version
routing_config {
additional_version_weights = {
aws_lambda_alias.canary_prod.function_version = 0.1
}
}
}Data handling in the immutable infrastructure model
As the compute resources themselves can come and go, data that needs to be persisted, including session state, has to be moved off of the compute tier. Depending on the type of data there are different AWS services at your disposal:
| Data type | Recommended AWS service (as starting point) |
| Application session data/state | Amazon ElastiCache Redis/Memcached |
| Application cache and temporary data | Amazon Elastic File System (EFS) [“NFS”] |
| Relational data | Amazon Aurora etc. |
| Non-relational data | Amazon DynamoDB etc. |
Conclusion
By adhering to the principle of never changing a running system, a higher degree of predictability and reliability can be achieved.
Many view rollbacks as a pain. Most people avoid spending time on rollback and disaster recovery testing. “We don’t do rollbacks, we prefer to try to fix the problem and roll forward”. This is a warning signal of manual procedures and lacking automation.
With the immutable infrastructure approach rollbacks becomes a natural part of change management. Database changes can be managed with the Expand-Contract pattern. Any failing automated checks with increased error rates should automatically roll back to the previously known working version, also supported by the database schema. By adopting canary releases and/or blue-green deployments rollbacks can be performed fast and with reduced end user impact.
A bonus with the Immutable Infrastructure approach is that rollbacks will become trivial. By releasing small changes frequently a failed new release shouldn’t be a big issue. Instead of being up at night or feeling the pressure of having to fight fires to resolve issues which are impacting end users, teams can investigate in peace and quiet, produce a new artifact version with the bug-fix and ship it quickly through fully automated and quality assured CI/CD pipelines, to master the art of Continuous Delivery and realize business value faster.
References
- https://repost.aws/knowledge-center/ec2-instance-crowdstrike-agent
- https://martinfowler.com/bliki/ImmutableServer.html
- AWS Well-Architected Framework REL08-BP04 Deploy using immutable infrastructure
- AWS Well-Architected Framework REL08-BP05 Deploy changes with automation
- AWS Well-Architected Framework OPS06-BP04 Automate testing and rollback
- AWS Well-Architected Framework OPS05-BP09 Make frequent, small, reversible changes
- https://12factor.net/processes
- https://netflixtechblog.com/ami-creation-with-aminator-98d627ca37b0
- AWS EC2 Image Builder User Guide