
Many Generative and Agentic AI blogs these days are about document processing and business workflow automation. This one is about elves. Read on to learn more about how I built this platform and the lessons that I learned.
Table of contents
- Introduction
- The unique value proposition of Naughty Elf Ideas
- Solution architecture of the Naughty Elf Ideas platform
- Idea generation flow walk-through
- Video generation flow walkthrough
- Choosing the right tool/model for each job
- Looking into the creative idea generation process
- Lessons learned
- Lesson 1: Construct prompts according to model provider guidance
- Lesson 2: Prompt engineering alone wasn't enough, RAG changed everything
- Lesson 3: LLMs doesn't follow "don't do X" – Use positive context instead
- Lesson 4: Multilingual translation challenges (Norwegian and Swedish)
- Lesson 5: AWS Step Functions vs. Amazon Bedrock Agents – Why I chose deterministic orchestration
- Conclusion
Introduction
With the increasingly popular tradition with the Elf on the Shelf (Naughty/Mischevious Elf, or “Rampenissen” in Norwegian), as December approaches, millions of parents all over the world face a similar challenge: what creative scenario should the Christmas elf get into tonight, to surprise their children? After a few years of the tradition, you’ve exhausted the classics; elf in flour mess, elf making snow angels in powdered sugar, elf zip-lining across the living room and toilet paper all over. You find yourself doom-scrolling Facebook groups and Pinterest until midnight, desperately searching for something your kids haven’t seen before.
At Sopra Steria, we help customers optimize processes and achieve business outcomes with technology. But in this case, I wanted to explore a more creative side – what would be possible when you push the boundaries of generative AI for inspiration rather than automation. This is my take on an innovation sandbox.
To solve this creative idea problem (primarily for my wife, but other parents could also probably profit ;-), just before AWS re:Invent 2025 I got the idea to dive deep into Generative and Agentic AI capabilities with Amazon Bedrock. I figure that a really useful tool would not be a static database of recycled ideas, but a complete platform that generates unlimited unique elf scenarios on demand — tailored to kids’ age, rooms in your house, and the mood you’re after (naughty, nice, nostalgia/pop culture). The result is https://naughtyelfideas.com/.
The unique value proposition of Naughty Elf Ideas
While traditional blog posts usually cover 20-80 recycled ideas, the Naughty Elf Ideas platform provides unlimited creative AI-generated ideas, based on the latest and most innovative Large Language Models (LLMs) from providers such as Anthropic and Amazon.
Traditional blogs have 0 personalization. This platform generates ideas according to your preferences for age group, room, mood, and it even accepts custom prompts. The site and ideas are tailored for local culture and language currently in English, Spanish, Norwegian and Swedish, with more to come!
Regular sites uses common stock photos or poorly lit cell phone snapshots. Here we generate unique images and video snippets of each idea.
Freshness is also on a whole new level, since new ideas are added by the community continuously. Users can vote for and rank the best ideas and share them in social media.
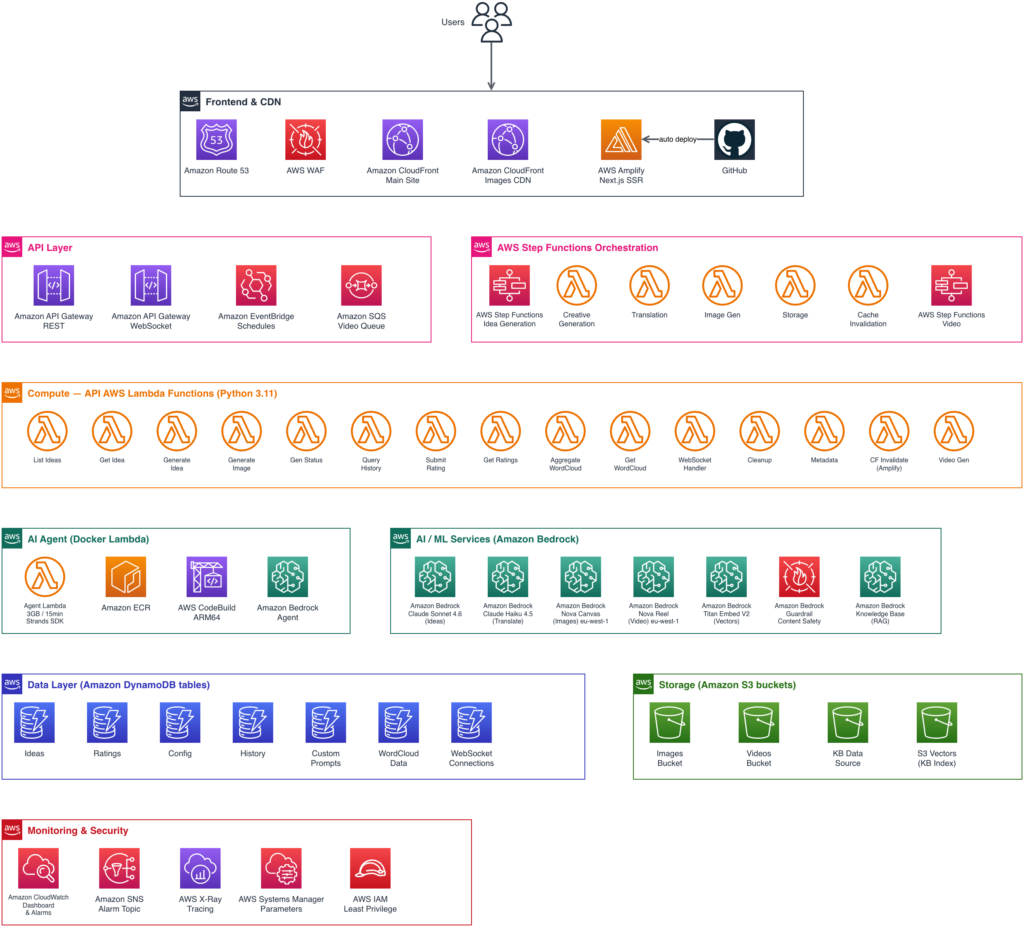
Solution architecture of the Naughty Elf Ideas platform
This is a real, live site which naturally receives the majority of it’s traffic in the months of late November and December. After Christmas, there’s no use for it. That’s why I chose pure serverless components from Amazon Web Services, to be able to scale according to demand. The remaining time of the year the baseline running costs are minimal.
Key components
- Fully serverless – no servers or databases to manage, scales automatically
- AWS Step Functions provides visual workflow orchestration with built-in error handling
- Multiple Amazon Bedrock models selected for specific tasks (more on this below)
- Amazon DynamoDB for idea storage with single-table design
- Amazon S3 + Amazon CloudFront for static assets (images, videos) with cache invalidation
- Next.js on AWS Amplify for SEO-optimized frontend with SSR/SSG
Overview of AWS architecture components
Idea generation flow walk-through
This is how the idea generation dialogue looks like:
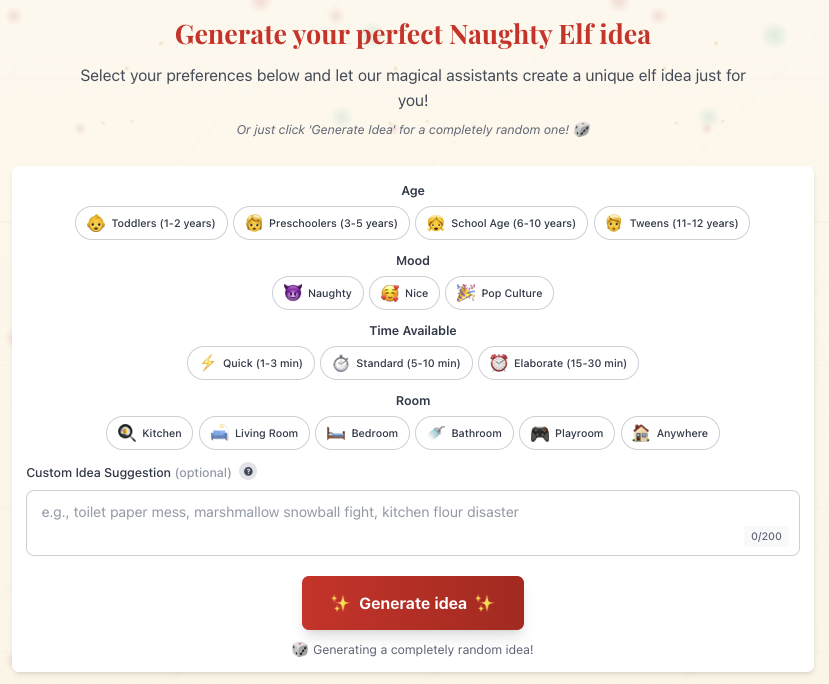
Excited users are not patient, so a challenge has been to optimize end-to-end processing to reduce waiting times to a minimum. Websockets dialogue mimics interaction during processing. The current total end-to-end processing time is about 30 seconds from request to complete idea, including translations to multiple languages and unique image generation. Parallel branches for translation and image generation reduces overall time-to-idea.
Idea generation orchestration with AWS Step Functions
One of the key architectural decisions was to identify the optimal workflow orchestration. I started out with Bedrock Agents, but quickly discovered it took well over 60-80 seconds every time. The AI reasoning overhead added latency at each decision point (which also incurred cost).
For a well-defined and repeatable workflow, there’s actually no need for AI Agent reasoning. The fastest and most cost efficient approach turned out to be a good, old State Machine. In addition, visual insight and debugging with log integrations in AWS Step Functions proved invaluable for troubleshooting.
Recommendation: Use Step Functions when the workflow is well-defined and latency matters; consider Bedrock Agents when you need dynamic reasoning and tool selection.
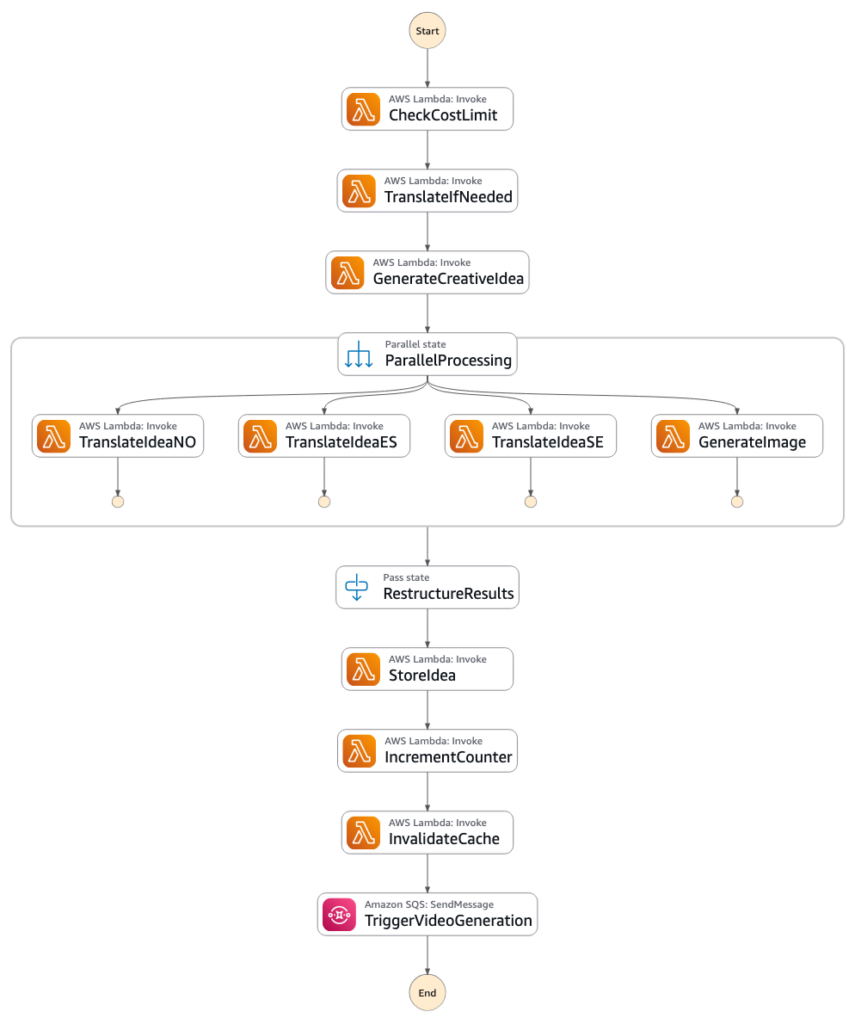
- End user clicks Generate idea along with preferred properties
- A POST /generate-idea call is sent to Amazon API Gateway which starts execution of an AWS Step Functions State Machine for Idea Generation
- To avoid bankrupting me in case the site goes really viral, I’ve set a cap on generation of max 100 ideas per day.
- If a custom prompt was provided in another language than English, translate it to English, which is the primary language of the system.
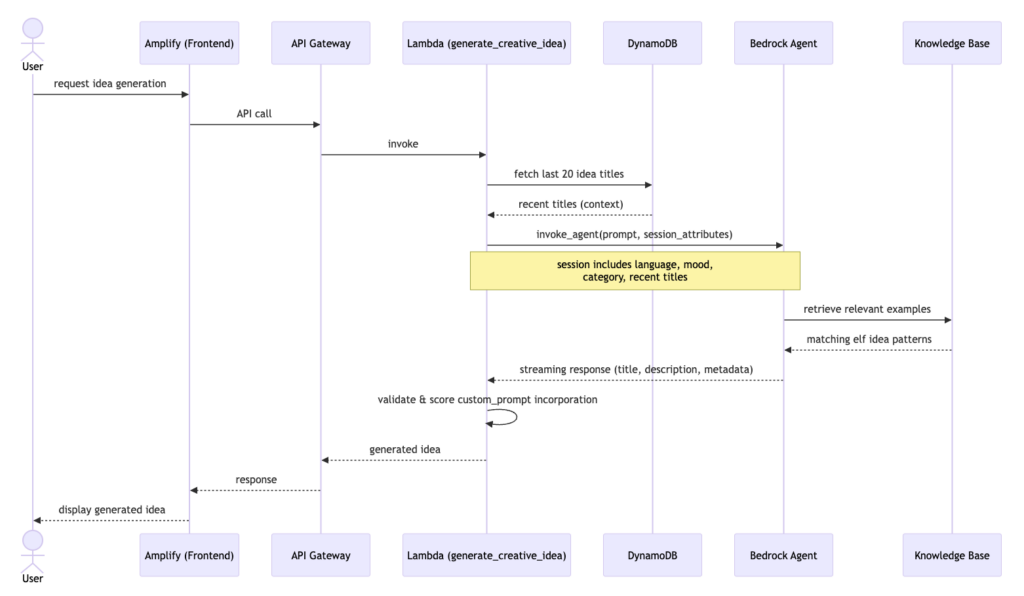
- Lambda function GenerateCreativeIdea invokes an Amazon Bedrock Agent wired up with a Bedrock Knowledge Base, to provide relevant context of historical ideas.
- I found the most creative ideas were provided by the latest version of Anthropic Sonnet.
- An Amazon Bedrock Guardrail is applied to ensure family friendly and safe ideas.
- When we have an original idea we enter a ParallelProcessing state.
- Translations to Norwegian, Spanish and Swedish – two-pass using Anthropic Haiku.
- Image generation with Amazon Nova Canvas based on idea description.
- Upon successful results the generated idea is stored in Amazon DynamoDB along with relevant metadata.
- The daily idea generator counter is incremented and relevant website pages are invalidated from Amazon Cloudfront.
- The final step is to put a message on an Amazon Simple Queue System (SQS) queue to generate a video snippet. This takes 2-3 minutes, and I didn’t want to keep the user waiting, so this is the reason for the decoupled, asynchronous process.
Video generation flow walkthrough
Same approach here; repeatable process => AWS Step Functions.
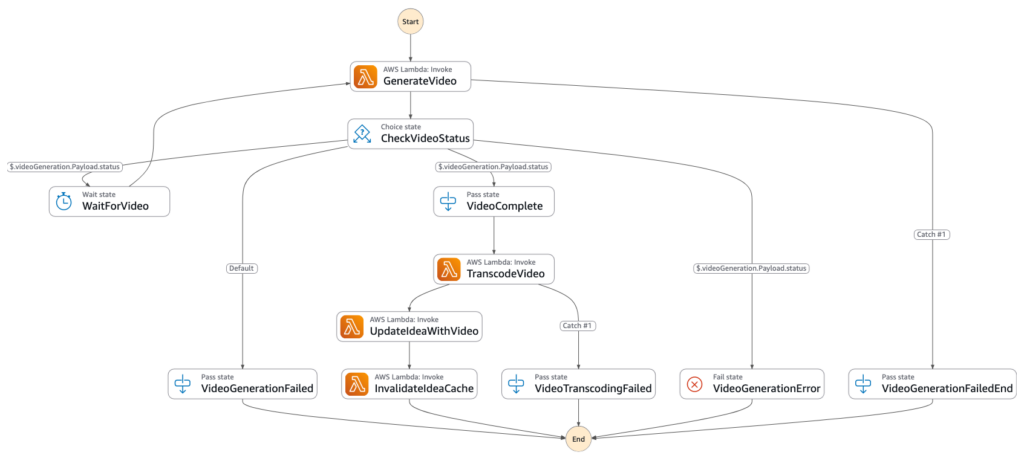
- The Amazon SQS queue which receives the message from the Idea Generation State Machine is configured with an AWS Lambda trigger which invokes the Video Generation State Machine.
- The AWS Lambda function GenerateVideo invokes Amazon Bedrock for video generation with Amazon Nova Reel.
- The original image is supplied for relevance.
- Raw video output is stored in Amazon S3.
- AWS Step Function logic waits and polls for video generation success or failure.
- When video generation completes, another Docker based AWS Lambda function uses FFmpeg to transcode the raw video file from S3 for web and file size optimization (for fast loading and data transfer cost control. An optimized version is saved back to Amazon S3 in a path configured as Amazon Cloudfront origin.
- The original idea is updated with metadata that a video is available.
- The main idea web page is invalidated from Amazon Cloudfront and the next page load displays a video overlay instead of the original image.
End-to-end this takes about 2 minutes and 25 seconds for a 6 second clip (current limitation in Amazon Nova Reel). Videos are progressive enhancements, they do not block the main idea flow.
Choosing the right tool/model for each job
To be able to get the results you are looking for it’s imperative to evaluate and benchmark relevant LLMs for different purposes. I ended up with the following:
| Task | Model selected | Rationale | Alternatives considered |
|---|---|---|---|
| Creative idea generation | Anthropic Claude Sonnet 4.6 | Most creative, contextually appropriate ideas | Claude Haiku (less creative), Nova Pro (good but less nuanced) |
| Norwegian and Swedish translation | Anthropic Claude Haiku 4.5 (two-pass) | Natural-sounding Norwegian/Swedish via two-pass approach | Nova models (did not produce acceptable results, suspect low training on these languages), Amazon Translate (too literal) |
| Spanish translation | Anthropic Claude Haiku 4.5 (two-pass) | Consistent quality across languages | Nova 2 Lite (acceptable, but standardized on Haiku as this was required for NO/SE) |
| Image generation | Amazon Nova Canvas | Cost-effective, good quality, AWS-native | Stability AI (higher quality, higher cost) |
| Video generation | Amazon Nova Reel | Only AWS-native option, 6-second clips (without complex stitching) | None (unique capability) |
Anthropic Claude Sonnet for ideas: Tested multiple models – Sonnet consistently produced the most creative, contextually appropriate elf ideas
Claude Haiku for Norwegian and Swedish: This was the hardest problem. Amazon Nova models were not acceptable out of the box for Scandinavian languages, and that’s not a surprise, taking into account the small population compared to the world’s major languages. Training on material from these languages have probably not been prioritized. Amazon Translate was even worse (too literal). The solution: a two-pass approach with Claude Haiku that first translates, then refines for natural flow, using Anthropic’s prompt guidelines. Low temperature (0.1) provides consistent translations. I discovered that higher temperature lead to creative interpretations and invention of new words :-).
Amazon Nova Canvas for images: Good balance of quality and cost. Stability AI was said to produce very high quality, but at 3x the cost, I went with Nova Canvas. I am looking forward to full Nova V2 suite availability.
Amazon Nova Reel for videos: The only AWS-native option for video generation. 6-second clips are perfect for social media sharing and preserving bandwidth charges.
Key take-away: Model selection should be validated through experimentation for each use case — don’t assume based on benchmarks. As new minor versions are released from the providers, expect upgrades in quality and relevance.
Looking into the creative idea generation process
Each idea on the site is generated on demand by an Amazon Bedrock Agent backed by an Amazon Bedrock Knowledge Base of existing elf ideas. When a request comes in, the agent doesn’t just freestyle, it receives a structured prompt that includes the target age group, the mood of the idea (naughty, nice, or popular culture/meme/nostalgia inspired), the desired room (optional) and a feed of the 20 most recently generated titles. This last part is key: rather than telling the model “don’t repeat yourself,” we hand it positive context; “here’s what already exists”, which language models handle far more reliably than negation constraints.
The Amazon Bedrock Knowledge Base grounds the output in proven, family-friendly formats, while the session attributes steer it toward something fresh and specific. The result is ideas that feel handpicked and personalized, rather than randomly generated.
Sequence diagram for the creative idea generation process
Let’s take a closer look at the Lambda function for idea creation. As it is hundreds of line of code, I’ve included a simplified pseudo-code example below to illustrate my approach.
function generate_creative_idea(language, custom_prompt, parameters, attempt):
1. READ agent config from env vars (AGENT_ID, AGENT_ALIAS_ID)
→ raise error if missing
2. RESOLVE parameters (category, mood, room)
→ randomly pick category from [toddlers, preschoolers, school-age, tweens] if not given
→ randomly pick mood from [naughty, nice, pop] if not given
→ map "naughty" → "mischievous" (safe alias to avoid content filter)
3. BUILD session attributes dict
→ always include: language, customPrompt, attempt
→ conditionally include: category, mood (safe alias), room
4. FETCH last 20 idea titles from DB
→ add as "recentIdeaTitles" to session attributes (positive context, not a prohibition)
5. RETRY LOOP (up to 3 attempts, exponential backoff):
a. BUILD input prompt via build_agent_input()
→ adjusts prompt wording if previous attempt was content-blocked
b. INVOKE Bedrock Agent (streaming)
→ pass session attributes + input text
# Actual Python snippet below
# Get agent configuration from environment
agent_id = os.environ.get('AGENT_ID')
agent_alias_id = os.environ.get('AGENT_ALIAS_ID')
knowledge_base_id = os.environ.get('KNOWLEDGE_BASE_ID')
if not agent_id or not agent_alias_id:
raise ValueError("Agent not configured: AGENT_ID and AGENT_ALIAS_ID environment variables required")
# Create Bedrock Agent Runtime client
bedrock_agent_runtime = boto3.client('bedrock-agent-runtime', region_name='eu-central-1')
# Retry configuration with exponential backoff
max_retries = 3
base_delay = 2 # seconds
# Track if previous attempt was content-blocked (to adjust prompt on retry)
content_blocked_retry = False
for retry_attempt in range(max_retries):
try:
# Rebuild input text each attempt — adjusts prompt if previous was blocked
input_text = build_agent_input(
category=category,
mood=safe_mood,
language=language,
custom_prompt=custom_prompt,
room=room,
attempt=attempt,
content_blocked=content_blocked_retry,
recent_titles=recent_titles
)
agent_start = time.time()
# Invoke agent with streaming response
response = bedrock_agent_runtime.invoke_agent(
agentId=agent_id,
agentAliasId=agent_alias_id,
sessionId=str(uuid.uuid4()),
sessionState={
'sessionAttributes': session_attributes
},
inputText=input_text
)
# Parse streaming response
idea_data = parse_agent_response(response)
c. PARSE streaming response → idea_data (title, description, metadata)
d. PUBLISH metrics (agent latency, KB citations)
e. ON SUCCESS → break loop
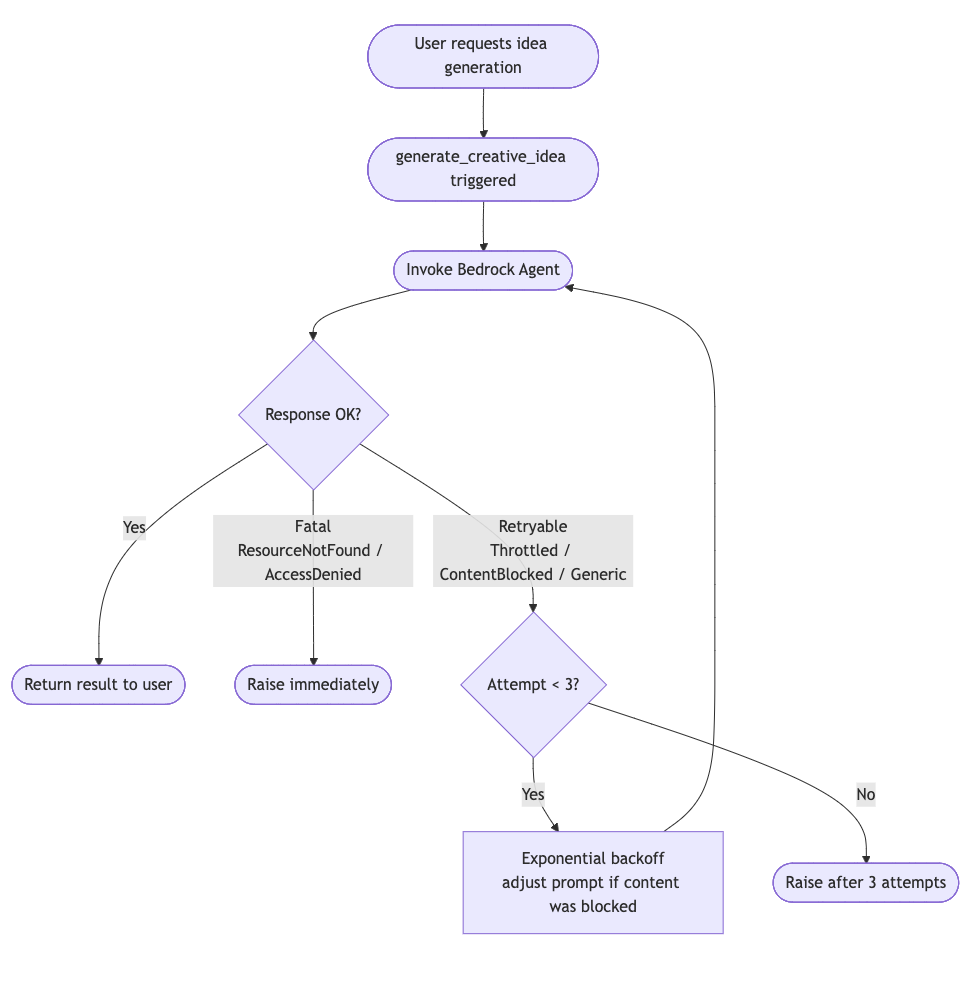
f. ON ContentBlockedError
→ if retries remain: set content_blocked_retry=True, wait, retry
→ else: raise
g. ON ThrottlingException
→ if retries remain: wait, retry
→ else: raise
h. ON ResourceNotFoundException / AccessDeniedException
→ raise immediately (no retry)
i. ON generic Exception
→ if retries remain: wait, retry
→ else: raise
6. WARN if total generation time > 45s (near Lambda timeout)
7. IF custom_prompt given:
→ score how well the output incorporated it
→ warn if score < 0.3
8. BUILD result dict:
→ title, description
→ metadata: category, mood (mapped back from safe alias), room, materials_type,
time_available, custom_prompt_score, kb_used flag
→ generation_time_ms
9. RETURN resultInfrastructure-as-Code for the Amazon Bedrock Agent implementation is handled with AWS Cloud Development Kit in Typescript, with specific and targeted agent instructions for the use-case. Tuning the prompts along with the Knowledge Base context was where I spent a lot of time to ensure relevant responses.
As there are many things that can go wrong in this process, content blocking by Amazon Bedrock Guardrails or safety filter in the language models themselves and Amazon Bedrock capacity constraints in certain regions, it is vital to remember the Well-Architected principle of REL05-BP03 Control and limit retry calls and implement proper retry and error handling.
Below is an example of the implemented logic for idea generation.
Lessons learned
As the concept of the Naughty/Mischievous Elf is creative, but with very specific boundaries about what’s acceptable and not, also taking into account cultural differences across countries, it was challenging to get the platform to produce relevant results in the beginning. As with most projects involving Artificial Intelligence, scoping, context and iterative testing and validation makes all the difference. Below I share my top five lessons learned.
Lesson 1: Construct prompts according to model provider guidance
Different models may expect prompts to be designed and structured in a particular way. Amazon Nova models and Anthropic Claude models expect input in different formats for optimal and relevant results. To get the results you’re after, check the model provider’s guidance. Keep the prompts version controlled so that you know what changed when results suddenly deviate. Test and benchmark until you’re happy. Amazon Bedrock Prompt Management may also be something to consider for more static prompts.
For Amazon Nova models see User Guide: Creating precise prompts. For Anthropic Claude models such as Opus, Sonnet or Haiku see Claude API Docs: Prompting best practices.
Lesson 2: Prompt engineering alone wasn’t enough, RAG changed everything
Problem: Initial prompts produced generic, uninspired elf ideas. Despite adding constraints, few-shot examples, and negative prompts, the process kept generating the same 3-5 ideas repeatedly. Most ideas agitated towards spillage, flour mess, toilet paper and so on.
What didn’t work:
- Adding more constraints to the prompt logic.
- Including few-shot examples of “good” ideas.
- Negative constraints (“avoid messy setups”, “no flour ideas”) – This amplified it and led to even more of them!
- Temperature adjustments (higher = more random, not more creative).
What actually worked: Retrieval Augmented Generation:
To help the model with more context I sourced ~150 unique ideas from other elf idea blogs and Pinterest boards and set up an Amazon Bedrock Knowledge Base with these ideas as inspiration (not to copy, but to provide a more comprehensive understanding of the creative space).
It had to be cost efficient, so Amazon OpenSearch was ruled out in favour of Amazon S3 Vectors. The agent now retrieves relevant examples before generating, dramatically improving variety and relevancy.
The feedback loop:
In the final part of the orchestration flow newly generated ideas are added back to the knowledge base, which creates a growing corpus of unique ideas. The more ideas generated, the more diverse future generations become. After 150+ ideas in the library, repetition dropped from ~30% to <5%.
Outcome: When I provided relevant Perceive context with Retrieval Augment Generation (RAG) and Amazon Bedrock Knowledge Bases, RAG expanded the creative space. This was a major breakthrough.
The language models themselves are supposed to be generic, based on the material they’re trained on. Prompt engineering on specialized or generic language models will only take you so far. My approach is to use the language models for reasoning, not the actual content (which also has a cut-off date after the model is trained and published). This is what most people don’t get. RAG is also faster and more cost-efficient than fine-tuning a model.
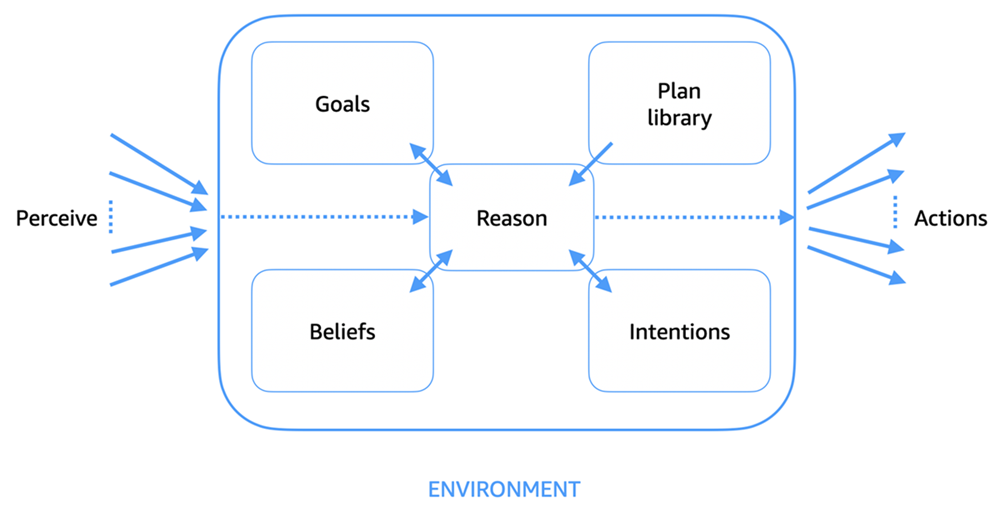
To illustrate the concept of Perceive, Reason and Act, the AWS Prescriptive Guidance: Foundations of agentic AI on AWS explains:
“At the core of every software agent is a cognitive cycle that is often described as the perceive, reason, act loop. This process is illustrated in the following diagram. It defines how agents operate autonomously in dynamic environments.”.
- Perceive: Agents gather information (for example, events, sensor inputs, or API signals) from the environment and update their internal state or beliefs.
- Reason: Agents analyze current beliefs, goals, and contextual knowledge by using a plan library or logic system. This process might involve goal prioritization, conflict resolution, or intention selection.
- Act: Agents select and execute actions that move them closer to achieving their delegated goals.
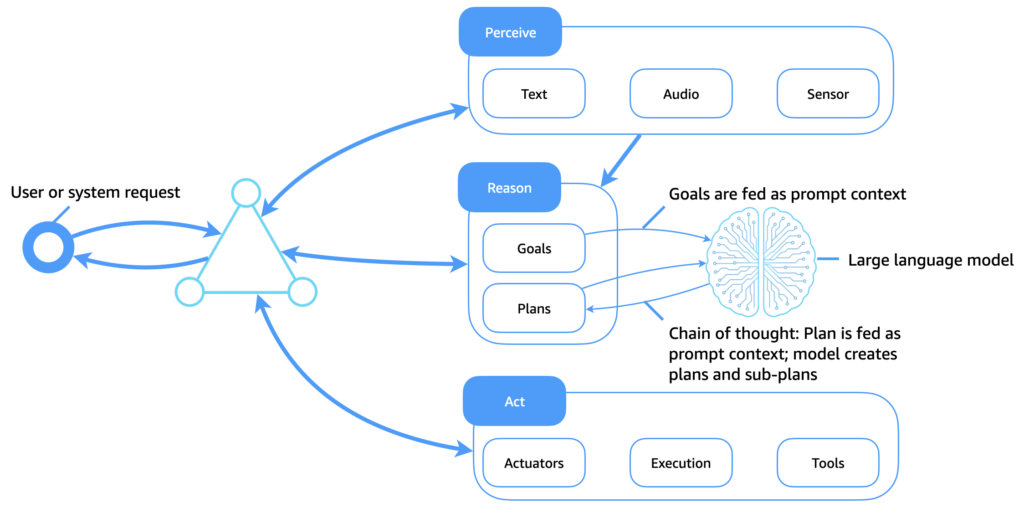
AWS Prescriptive Guidance: Generative AI agents: replacing symbolic logic with LLMs
“The following diagram illustrates how large language models (LLMs) now serve as a flexible and intelligent cognitive core for software agents. In contrast to traditional symbolic logic systems, which rely on static plan libraries and hand-coded rules, LLMs enable adaptive reasoning, contextual planning, and dynamic tool use, which transform how agents perceive, reason, and act.”
Lesson 3: LLMs doesn’t follow “don’t do X” – Use positive context instead
Problem: After a few hundred ideas, the system started generating duplicates. Two ideas generated 32 minutes apart were essentially the same concept — “elf swaps everyone’s phone contact names” — despite the Amazon Bedrock Knowledge Base similarity check that was supposed to catch this.
Why the Knowledge Base similarity check wasn’t enough: The check fired after generation. By then, the Amazon Bedrock call had already been made and billed. Worse, the first generated idea got added back to the Amazon Bedrock Knowledge Base, so the second generation retrieves it as a reference, and the model riffs on it rather than diverging from it.
The instinct and why it doesn’t work: The obvious fix is to pass recent idea titles to the agent with a “don’t repeat these” instruction. This is a well-documented failure mode: LLMs are poor at negation constraints. “Don’t generate X” makes X more salient in the model’s attention, not less. The model acknowledges the constraint, then gravitates toward the same concepts anyway.
What actually works: positive context framing: According to Claude API Docs: Add context to improve performance: Providing context or motivation behind your instructions, such as explaining to Claude why such behavior is important, can help Claude better understand your goals and deliver more targeted responses.
Less effective: NEVER use ellipses
More effective: Your response will be read aloud by a text-to-speech engine, so never use ellipses since the text-to-speech engine will not know how to pronounce them.
Taking this into consideration, instead of “avoid these ideas”, I framed it as “here’s what already exists, explore a different domain”:
# ❌ Negation framing — doesn't work reliably
parts.append("Do NOT generate ideas similar to these recent ones:")
for title in recent_titles:
parts.append(f" - {title}")
# ✅ Positive context framing — works with how LLMs process context
parts.append("STEP 3: These ideas have been generated recently — create something in a DIFFERENT domain:")
for title in recent_titles[:10]:
parts.append(f" - {title}")
The model uses the list as context about what’s already covered and naturally diverges. It’s the same information, but framed as situational awareness rather than a prohibition.
The implementation: Before invoking the agent, fetch_recent_idea_titles() queries DynamoDB’s StatusIndex for the 20 most recent active ideas (newest first, projection on translations only for efficiency). The titles are joined as a pipe-separated string in sessionAttributes['recentIdeaTitles'] and also injected into the prompt as step 3. Fails are open, a DynamoDB error never blocks generation.
Defense in depth: The pre-generation context reduces the probability of duplicates. The post-generation check_similar_ideas() in catches anything that slips through, and the Step Function retries with attempt=2.
Key insight: LLMs process context, not rules. “Here’s what exists” is context. “Don’t do X” is a rule. Context wins.
Lesson 4: Multilingual translation challenges (Norwegian and Swedish)
Problem: Spanish translations were okay, but Norwegian and Swedish translations were awkward and unnatural. Results with Amazon Nova Pro/Lite models were not acceptable out of the box. Amazon Translate was even worse – too literal, missing cultural nuance.
Approach: I tested multiple models: Amazon Nova Pro, Amazon Nova 2 Lite, Amazon Translate, Anthropic Claude Haiku and Anthropic Claude Sonnet.
From the AWS AI Service Card overview on Amazon Nova Models – Language:
Amazon Nova models are released as generally available for English, German, French, Spanish, Italian, Portuguese, Japanese, Hindi, and Arabic. Amazon Nova model’s guardrails are intended for use in the aforementioned languages only, however Amazon Nova models are trained and will attempt to provide completions in up to 200 languages. In use cases beyond the languages identified above, customers should carefully check completions for effectiveness, including safety.
Reference: https://docs.aws.amazon.com/ai/responsible-ai/nova-micro-lite-pro/overview.html
From Anthropic Claude API Docs: Multilingual support:
Claude excels at tasks across multiple languages, maintaining strong cross-lingual performance relative to English.
Claude demonstrates robust multilingual capabilities, with particularly strong performance in zero-shot tasks across languages. The model maintains consistent relative performance across both widely-spoken and lower-resource languages, making it a reliable choice for multilingual applications.
Reference: https://platform.claude.com/docs/en/build-with-claude/multilingual-support
A two-pass approach with Claude Haiku produced the best results at a reasonable price point:
- First pass: Direct translation
- Second pass: “Refine this Norwegian text to sound natural, as if written by a native speaker”
Outcome: Natural Norwegian and Swedish like a native speaker would write it. Two-pass added ~2-3 seconds of latency, but it was definitely worth it. Claude’s broader multilingual training data made the difference, and the most lightweight option with Haiku did the trick, at the best performance and price.
Lesson 5: AWS Step Functions vs. Amazon Bedrock Agents – Why I chose deterministic orchestration
Problem: The first version of the idea generation workflow was a mess. Too many fine-grained states, no parallel processing, and a failed experiment with Amazon Bedrock Agents that added 40-70 seconds of latency I couldn’t explain at first.
First iteration: The Amazon Bedrock Agent experiment
In the initial iteration the orchestration layer was based on Amazon Bedrock Agents. The appeal was obvious; natural language instructions, dynamic tool selection, no explicit state machine to maintain. In theory, you describe what you want and the agent figures out the steps.
In practice, it was the wrong tool for this job. The agent’s reasoning loop – deciding which tool to call, in what order, with what parameters – added ~45-70 seconds of overhead on top of the actual model invocations. For a workflow where the involved steps are known in advance (generate idea → translate → generate image → store ++), that reasoning overhead provides zero value. You’re paying for flexibility you don’t need.
Next iteration: AWS Step Functions
Defining all steps in the process in an AWS Step Functions State Machine was relatively straight forward, and i set up the idea generation step is a separate AWS Lambda function, invoking the Bedrock Agent for the creative reasoning process only. This cut the processing time in half and also provided better visibility into the end-to-end workflow.
Comparison of orchestration workflow alternatives
| Dimension | AWS Step Functions | Amazon Bedrock Agents |
|---|---|---|
| Control & predictability | ✅ Deterministic, explicit state transitions | ⚠️ AI-driven, non-deterministic paths |
| Latency | ✅ ~15-25s for idea generation | ❌ ~45-90s due to reasoning overhead |
| Cost model | ✅ Pay per state transition | ⚠️ Pay per token + reasoning tokens |
| Flexibility | ⚠️ Requires code changes for new flows | ✅ Natural language instructions |
| Operational complexity | ✅ Visual debugging, built-in retries | ⚠️ Black-box reasoning, harder to debug |
| Best for | ✅ Well-defined, latency-sensitive workflows | ✅ Dynamic, exploratory tasks |
The latency difference alone was disqualifying. Parents using the site at 11 PM won’t have the patience to wait two minutes seconds for an idea. But the operational complexity gap matters just as much in practice; when an Amazon Bedrock Agent fails, you get a vague error from the reasoning loop (out of the box) and you have to add more logging for debugging capabilities. When an AWS Step Functions state fails, you see exactly which state, with the full input/output, on a visual timeline.
Experiences with AWS Step Functions orchestration:
The initial Step Functions workflow had its own problems — too many fine-grained states that should have been a single Lambda call, and no parallel processing. Consolidating related operations and adding parallel branches for translation and image generation brought execution time from ~45s down to ~20s.
- Consolidated related operations into single Lambda functions (fewer state transitions, less overhead)
- Used parallel branches for translation and image generation — they’re independent, so there’s no reason to run them sequentially
- Added explicit error handling states with retry logic instead of relying on default behavior
- Implemented cost limit checks at the start to fail fast before any expensive model invocations
Key takeaway: Use AWS Step Functions when the workflow is well-defined and the steps are known in advance. Use Amazon Bedrock Agents when you genuinely need dynamic reasoning – when the agent needs to decide which tools to call based on context, or when the workflow varies significantly between executions. For content generation pipelines with fixed steps, AWS Step Functions wins on every dimension that matters: latency, cost, debuggability, and predictability.
Outcome: Overall execution time ~90-60 seconds → ~30 seconds. The AWS Step Functions visual debugger has saved me hours of troubleshooting – being able to replay a failed execution with the exact input/output at each state is invaluable.
Conclusion
Building this site just for fun to push the boundaries of creative capabilities with Generative AI on AWS has been really cool and inspiring. I’ve learned a lot during the process which will also be extremely valuable when implementing customer solutions.
Key takeaways
- As Generative and Agentic AI technology matures, more and more use-cases emerge – But, to meet expectations, solution design requires careful orchestration, model benchmarking and output quality assurance.
- Model capabilities are also developing fast – Stay up to date on the recent advances and availability of new model versions to experience even more accurate and high quality results.
- Model selection requires empirical testing – benchmarks don’t tell the whole story, especially for sub-major languages.
- AWS Step Functions beats Amazon Bedrock Agents for deterministic workflows – the latency difference could be significant (~30s vs ~60-120s in this case). Use Agent orchestration for non-deterministic scenarios or where you need to handle unknown edge cases.
- Content safety is solvable – Amazon Bedrock Guardrails provides enterprise-grade filtering with minimal latency impact. Also, some model providers have built-in content safety filters.
- Serverless scales effortlessly – the architecture handles traffic spikes during the Christmas season without intervention.
- Spec-driven development with Kiro boost innovation – Leveraging Kiro along with a maturing base of agent/project steering definitions, MCP servers and subagents really amplified development velocity and learning outcomes.
Future enhancements
Some ideas currently in the backlog:
- User accounts for saving favorite ideas and tracking which ones you’ve used.
- Personalization based on past preferences and household setup.
- December planning mode: Generate a full month of ideas in one go – no more nightly scrambling.
- Weekly elf calendar: Get a curated week of ideas that build on each other (storyline mode).
- Difficulty progression: Start simple in early December, escalate to elaborate setups as Christmas approaches.
- Integration with smart home devices (imagine the elf controlling your speakers and Christmas tree lights)!
- Collaborative features: Share your elf calendar with your partner so you can take turns.
- Portal support for additional languages (German, French).
Try it out yourself!
Visit naughtyelfideas.com to see it in action and generate your own unique elf idea.
Let me know what you think, feedback is welcome!